名刺OCR API機能の実装(Google Vision API+独自AIモデル+kintoneとの連携)
本ブログの更新をすっかりご無沙汰しておりました。
昨年春にE資格を取得して、昨年4月には前の会社を早期退職しました。 フリーランスとしてデータ分析やAI案件獲得を目指していましたが、実務経験がないことが足枷となり、なかなか難しいなと感じていたところ、縁あって昨年夏からIT系企業に勤めています。
また、昨年後半には、経産省主催のAI人材育成プログラムであるAI Quest2021に参加したり、ディープラーニング協会の運営のサポートメンバーをしたり、公私にわたり忙しく、なかなかブログ更新ができておりませんでした(言い訳です)。
そうした中で、社内プロジェクトの一環で掲題に関する開発を行いましたので、その概要について説明したいと思います。
1. 全体像

名刺アプリ全体像は、上図の通りであり、「名刺管理アプリ(kintone側)」と「名刺OCR-API機能(GCP側)」の2つから構成されています。 言語としては、kintone側がJavascript、GCP(Google Cloud Platform)側がPythonを利用しています。
そうそう説明が前後してしまいましたが、kintoneとは、サイボウズ社が提供している、webデータベース型の業務アプリ構築クラウドサービスです。いわゆるPaaS(Platform as a Service)に該当するサービスです。さまざまな業種や職種の業務に合わせたオリジナルアプリをノーコードで簡単に作成できますが、標準機能を超えてカスタマイズをしようとするとJavascript(但し、独自性が強いところがあり)を利用する必要があります。
GCP側は以下の機能を使っています。
Vision API
Vision APIは、GCPが提供する機械学習サービスの一種です。 このサービスを利用することで、Googleの持つ画像に関する機械学習モデルを使い、対象となる画像から様々な情報を取得することが可能です。今回は画像からテキストとそのテキストが画像のどの箇所にあるかという位置情報を取得して、利用しています。
Cloud Run
Cloud Run は、いわゆるサーバーレスサービスであり、Docker等のコンテナを実行できる環境です。マシンの構成やトラフィックに応じた自動スケーリングについて心配することなく、サーバーレス HTTP コンテナをデプロイしてスケールするためのフルマネージドなサービスということです。
Cloud Endpoints
Cloud Endpointsは、APIを認証・管理するためのサービスです。
Cloud Storage
Cloud Stroageは、GCPが提供しているオンラインストレージサービスです。Google Driveと比較して、GCPの各サービスとの連携が容易という特徴があります。
Cloud Scheduler
cron のようにジョブの定時実行を行うことのできるサービスです。 任意のHTTPエンドポイントにリクエストを投げることなどが可能です。Cloud Runがサービスを利用していないと停止して、次に呼び出した際にCold Startしてしまうため、立ち上がりまでに時間がかかってしまいます。そこで、本機能を利用して、日中Cloud Runが停止することを避けるために利用しています。
2. 独自AIモデル
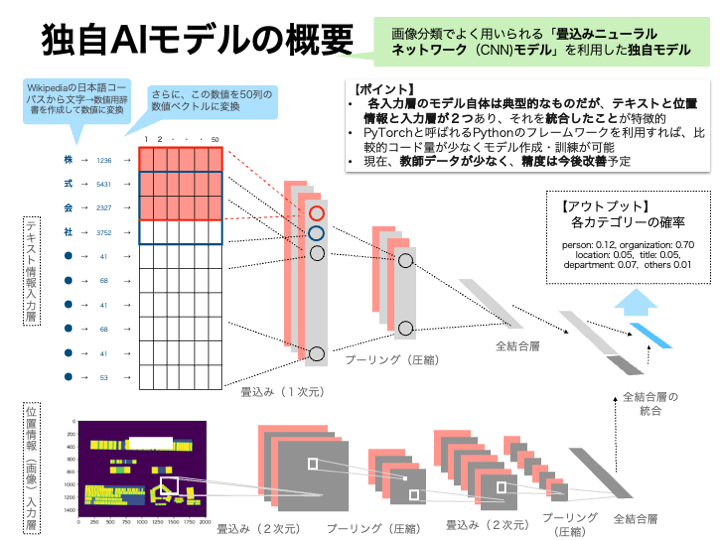
GCPではNatural Language APIが提供されていて、その中で「エンティティ分析」という機能があります。具体的には、指定されたテキストに既知のエンティティ(人名、ランドマークなどの固有名詞)が含まれていないかどうかを調べて、それらのエンティティに関する情報を返すサービスです。ただ、名刺の分類で必要な役職やタイトル、部署・住所などが抽出できないし、文章ではなく単語ベースでは精度が悪いので、名刺OCRには適用が難しいので、独自モデルを作成することにしました。
Vision APIでは、画像からテキストを抽出するだけではなく、テキストの位置情報(画像の中でどこにあるかという情報で、テキストを囲む矩形の頂点の位置情報)もデータとして返ってくるので、(双方を利用した方が精度が良いだろうという仮説を元に)双方を利用することにしたものです(体感ではテキストのみを利用したものより精度が良いですが、現時点ではデータが少なく検証までは至っていません😅)。
モデルとしてはテキスト分類でも相応の精度となるCNNモデルを利用しています。CNNだと位置情報を画像化して統合もしやすいのでそうしたメリットもあります。なお、文章等を分類する場合には、辞書を利用して単語毎にTokenizerで分けて数値化するのが通常だと思いますが、名前や会社名・役職等の対象が短いので、文字ベースでテキストを数値化しています。
3. API連携の流れ
- kintoneの名刺管理アプリ等のアプリケーション側で、名刺画像をbase64形式に変換したうえで、以下の通り設定(json形式)してEndpointsにrequestsを送付します
- headersとして
{'Content-Type': 'application/json'} - dataとして
{'requests': [{'images': {'content': base64形式に変換した画像 }]}
- headersとして
- 名刺OCR機能(API)側で処理を行い、その結果を以下の通り返します(json形式)
{'department': 'xxxx部',
'email': 'akatak-blog@xxxx.co.jp',
'fax': '03-xxxx-xxxx',
'location': '東京都xx区xxx-xxx-xxx,
'mobile': '03-xxxx-xxxx',
'organization': '株式会社xxxxxxxx',
'other': 'xxxx, xx"
'person': '',
'tel': '03-xxxx-xxxx',
'title': 'xx長',
'web': 'http//www.xxx.co.jp/'}
- kintoneの名刺管理アプリ等のアプリケーション側で、受け取ったjsonを元に、仕様に基づき適宜データを保存します
4. Google Cloud Platform(GCP)側の処理
- 画像データ(base64形式)をVision APIに送付します。
- テキストデータと位置情報が返ってくるので、それらの情報に基づき、位置が近いテキストをひとまとまりのブロックにします。
- そのブロック毎のテキストに対して、正規表現を利用して、電話番号・ファックス・郵便番号などを抽出します。
- 抽出されなかったブロック毎のテキストを、訓練済みの独自AIモデルに投入し、分類結果を取得します。
- 正規表現に基づいた分類結果とAIモデルによる分類結果を統合し、結果を返します。
5. 実際のAIモデル
モデルの実装はPytorchで行っています。まだ、モデルを訓練するにあたり、Vision APIにより位置情報のある名刺データが少ないため、テキストデータのみに基づくモデル(TextCNNModel)で事前学習をしておき、そこで得られたパラメータを初期値として統合モデル(IntegratedCNNModel)Vision APIにより得られたテキスト+位置情報を元にしたデータに元に転移学習を行いました。
class IntegratedCNNModel(nn.Module): def __init__(self, vocab_size=10000, emb_size=50, filters=128, text_model_initials=None, requires_grad=True): super(IntegratedCNNModel, self).__init__() self.filters = filters self.embedding = nn.Embedding(num_embeddings=vocab_size, embedding_dim=emb_size, padding_idx=0) self.text_conv = nn.Conv2d(in_channels=1, out_channels=filters, kernel_size=(3, emb_size), stride=1) self.text_fc = nn.Linear(128, 64) self.dropout1 = nn.Dropout(0.5) self.dropout2 = nn.Dropout(0.25) self.conv1 = nn.Conv2d(1, 16, 3, 1) self.conv2 = nn.Conv2d(16, 32, 3, 1) self.fc1 = nn.Linear(28800, 1280) self.fc2 = nn.Linear(1280, 6) self.fc_all = nn.Linear(64 + 6, 6) if text_model_initials: self.embedding.weight = nn.Parameter(text_model_initials['embedding.weight'], requires_grad=requires_grad) self.text_conv.weight = nn.Parameter(text_model_initials['conv.weight'], requires_grad=requires_grad) self.text_conv.bias = nn.Parameter(text_model_initials['conv.bias'], requires_grad=requires_grad) self.text_fc.weight = nn.Parameter(text_model_initials['fc1.weight'], requires_grad=requires_grad) self.text_fc.bias = nn.Parameter(text_model_initials['fc1.bias'], requires_grad=requires_grad) def forward(self, in_text, in_pos): x1 = self.embedding(in_text) x1 = self.text_conv(x1) x1 = F.relu(x1) x1 = F.max_pool2d(x1, kernel_size=(x1.size()[2], 1)) x1 = self.dropout1(x1) x1 = x1.view(-1, self.filters) x1 = self.text_fc(x1) x2 = self.conv1(in_pos) x2 = F.relu(x2) x2 = self.conv2(x2) x2 = F.relu(x2) x2 = F.max_pool2d(x2, 2) x2 = self.dropout1(x2) x2 = torch.flatten(x2, 1) x2 = self.fc1(x2) x2 = self.dropout2(x2) x2 = self.fc2(x2) x = torch.cat([x1, x2], dim=1) x = self.fc_all(x) output = F.softmax(x, dim=1) return output
class TextCNNModel(nn.Module): def __init__(self, vocab_size=10000, emb_size=50, filters=128): super(TextCNNModel, self).__init__() self.filters = filters self.embedding = nn.Embedding(num_embeddings=vocab_size, embedding_dim=emb_size, padding_idx=0) self.conv = nn.Conv2d(in_channels=1, out_channels=filters, kernel_size=(3, emb_size), stride=1) self.dropout = nn.Dropout(0.5) self.fc1 = nn.Linear(128, 64) self.fc2 = nn.Linear(64, 6) def forward(self, x): x = self.embedding(x) x = x.unsqueeze(1) x = self.conv(x) x = F.relu(x) x = F.max_pool2d(x, kernel_size=(x.size()[2], 1)) x = self.dropout(x) x = x.view(-1, self.filters) x = self.fc1(x) x = self.dropout(x) x = F.relu(x) x = self.fc2(x) output = F.softmax(x, dim=1) return output
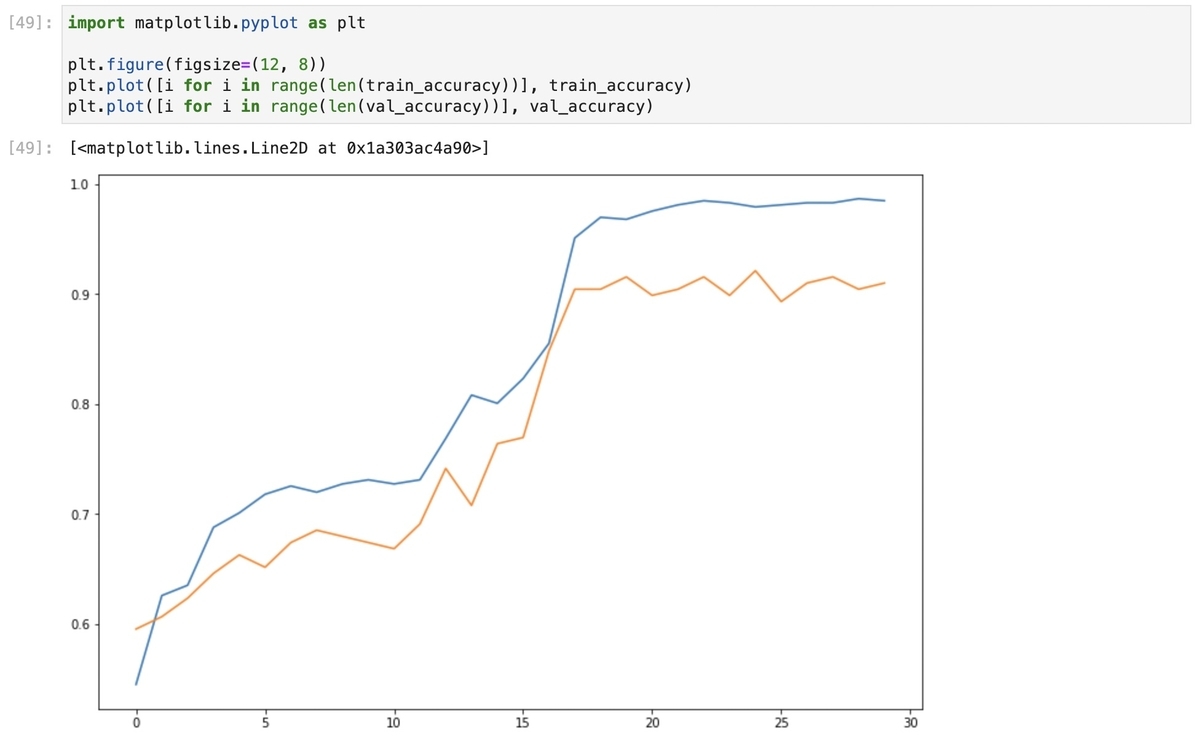
6. 学習結果
転移学習の結果は以下の通りです。
# 学習 tracker = 0 train_loss = [] val_loss = [] train_accuracy = [] val_accuracy = [] model.train() for i in range(epochs): _train_loss = 0.0 _train_acc = 0.0 for X_text, X_pos, y in train_dataloader: tracker += 1 optimizer.zero_grad() output = model.forward(X_text, X_pos) loss = criterion(output, y) _, preds = torch.max(output, 1) loss.backward() optimizer.step() _train_loss += loss.item() _train_acc += torch.sum(preds==y).item() train_loss.append(_train_loss) train_epoch_acc = _train_acc / len(train_dataloader.dataset) train_accuracy.append(train_epoch_acc) _val_loss = 0.0 _val_acc = 0.0 with torch.no_grad(): for X_text, X_pos, y in val_dataloader: output = model.forward(X_text, X_pos) loss = criterion(output, y) _, preds = torch.max(output, 1) _val_loss += loss.item() _val_acc += torch.sum(preds==y).item() val_loss.append(_val_loss) val_epoch_acc = _val_acc /len(val_dataloader.dataset) val_accuracy.append(val_epoch_acc) model.train() print("epoch", i, "\ttrain loss", round(_train_loss, 4), "\ttrain accuracy", round(train_epoch_acc, 4), "\tval loss", round(_val_loss, 4), "\tval accuracy", round(val_epoch_acc, 4))
epoch 0 train loss 25.3956 train accuracy 0.5451 val loss 65.1692 val accuracy 0.5955 epoch 1 train loss 24.1934 train accuracy 0.6259 val loss 64.4132 val accuracy 0.6067 epoch 2 train loss 23.999 train accuracy 0.6353 val loss 64.016 val accuracy 0.6236 epoch 3 train loss 23.0829 train accuracy 0.688 val loss 62.8315 val accuracy 0.6461 epoch 4 train loss 22.7322 train accuracy 0.7011 val loss 62.4082 val accuracy 0.6629 epoch 5 train loss 22.415 train accuracy 0.718 val loss 62.6237 val accuracy 0.6517 epoch 6 train loss 22.3255 train accuracy 0.7256 val loss 61.8551 val accuracy 0.6742 epoch 7 train loss 22.4764 train accuracy 0.7199 val loss 61.0919 val accuracy 0.6854 epoch 8 train loss 22.4273 train accuracy 0.7274 val loss 61.4489 val accuracy 0.6798 epoch 9 train loss 22.3758 train accuracy 0.7312 val loss 61.378 val accuracy 0.6742 epoch 10 train loss 22.227 train accuracy 0.7274 val loss 61.4148 val accuracy 0.6685 epoch 11 train loss 22.2422 train accuracy 0.7312 val loss 61.0007 val accuracy 0.691 epoch 12 train loss 21.6772 train accuracy 0.7688 val loss 57.9652 val accuracy 0.7416 epoch 13 train loss 20.9931 train accuracy 0.8083 val loss 59.2871 val accuracy 0.7079 epoch 14 train loss 21.0462 train accuracy 0.8008 val loss 57.5888 val accuracy 0.764 epoch 15 train loss 20.7282 train accuracy 0.8233 val loss 57.1339 val accuracy 0.7697 epoch 16 train loss 20.1716 train accuracy 0.8553 val loss 53.9223 val accuracy 0.8483 epoch 17 train loss 18.5937 train accuracy 0.9511 val loss 51.2095 val accuracy 0.9045 epoch 18 train loss 18.3057 train accuracy 0.9699 val loss 51.0726 val accuracy 0.9045 epoch 19 train loss 18.3522 train accuracy 0.968 val loss 50.8161 val accuracy 0.9157 epoch 20 train loss 18.2825 train accuracy 0.9756 val loss 51.461 val accuracy 0.8989 epoch 21 train loss 18.1666 train accuracy 0.9812 val loss 50.8358 val accuracy 0.9045 epoch 22 train loss 18.0271 train accuracy 0.985 val loss 50.7952 val accuracy 0.9157 epoch 23 train loss 18.0518 train accuracy 0.9831 val loss 51.1253 val accuracy 0.8989 epoch 24 train loss 18.1432 train accuracy 0.9793 val loss 50.6701 val accuracy 0.9213 epoch 25 train loss 18.0733 train accuracy 0.9812 val loss 51.279 val accuracy 0.8933 epoch 26 train loss 18.0739 train accuracy 0.9831 val loss 50.7902 val accuracy 0.9101 epoch 27 train loss 18.0383 train accuracy 0.9831 val loss 50.4226 val accuracy 0.9157 epoch 28 train loss 17.9971 train accuracy 0.9868 val loss 50.9058 val accuracy 0.9045 epoch 29 train loss 18.014 train accuracy 0.985 val loss 50.8351 val accuracy 0.9101
テストデータを適用すると、以下の通り93%の精度となりました。 今後、データを蓄積した上で、精度改善を図っていく予定です。
JDLAのE資格(2021#1)に合格しました!私の勉強法などまとめました
ブログの更新も大変ご無沙汰となってしまいました。
実は昨年10月から日本ディープラーニング協会(JDLA)のE資格試験に挑戦するための認定講座を受講し始め、本年2月に開催されたE資格試験を受験しました。 そのため、この半年間は試験関連の勉強に専念、特に直前2〜3ヶ月は本当に集中的に勉強しました。
なので、ブログの更新もその間失礼させていただきました。
しかし、こんなに集中して勉強したのは大学受験以来という感じではありました(ちょっと言い過ぎ?他にもこれまで資格試験には挑戦してきましたので、それ以降久しぶりにというのが正解かもしれません)。50代半ばに差し掛かっていても、新しいことを集中的に学ぶのが苦にならなかったのは本当に嬉しい発見です。
その甲斐もあって、昨日メールにて以下の案内がきましたが、相応の得点率でE資格試験に合格することが出来ました!💮

優秀賞を目指してましたが、2019年#1で5名程度だったので、とても無理でした。ははは。
しかし、今年は結果発表が遅かったですね。昨年比1週間以上も遅く、皆さんがヤキモキしているのがSNS等で伝わってきました。昨年8月の試験がコロナ禍で中止となったため、受験者が多かったことが影響したのでしょうか。
さて、今回E資格を取得するに当たり、どのように勉強したかについて、簡単に書きたいと思います。
JDLA認定プログラム
まず、E資格を取得するためには、JDLA認定プログラムの受講を終了する必要があるのですよね。僕は、昨年9月時点で色々調べて当時受講料が安く、当時94%が合格という宣伝文句のAvilenさんのプログラム「全人類のためのE資格コース」を受講することにしました。
結果的にはAvilenさんを選んでとても良かったと思います。オンライン講座が分かりやすかったのはもちろんですが、何より繰り返しできる問題を数多く提供しているので、直前の知識の定着化に大いに役立ちました。また、Avilenさんが提供する模試の問題も練られており、寧ろ本番の問題が簡単に感じるほどで、大変勉強になりました。
さらには、Slackで質問し放題。私自身は質問を多くはしませんでしたが、他の方の質問やそれに対する回答はかなり参考にさせていただきました。同じ目標に向かって頑張っている方の存在は、大いに励みになりましたし、また、色々な情報共有もなされていてとても助かりました。
参考図書
上記のAvilenさんの講座だけでも、もしかしたら合格には十分だったかも知れませんが、私の場合、高得点を狙いにいきましたので、書籍でも知識の強化を諮りました。E資格取得を目指されている方の参考になれば幸いです。
お薦め本
JDLAの推薦図書からは、やはり次の2冊は外せません。
①ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装

ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装
- 作者:斎藤 康毅
- 発売日: 2016/09/24
- メディア: 単行本(ソフトカバー)
②ゼロから作るDeep Learning ―自然言語処理編

ゼロから作るDeep Learning ❷ ―自然言語処理編
- 作者:斎藤 康毅
- 発売日: 2018/07/21
- メディア: 単行本(ソフトカバー)
どちらも基本的にPythonと数値計算ライブラリのnumpyなど最小限のライブラリだけを利用して、Deep Learningの様々なモデルや機能を、基本的な概念の説明と合わせて実装していく書籍です。概念も実装も丁寧に説明されており、非常に分かりやすく、E資格試験の「ソースコードを含む問題については、Pythonで記述し、かつTensorFlow等の機械学習系ライブラリに依存しない問題を出題」への対応にもなります。お勧めというより、E資格取得に際しては必読と言っても良いでしょう。
次にご紹介するのは、通称「黒本」と呼ばれている「徹底攻略ディープラーニングE資格エンジニア問題集」です。
③徹底攻略ディープラーニングE資格エンジニア問題集

徹底攻略ディープラーニングE資格エンジニア問題集 徹底攻略シリーズ
- 作者:スキルアップAI株式会社 小縣 信也,スキルアップAI株式会社 斉藤 翔汰,スキルアップAI株式会社 溝口 聡,スキルアップAI株式会社 若杉 一幸
- 発売日: 2020/09/04
- メディア: Kindle版
Amazonの書評では酷評されていますね。確かに初版で誤植が多すぎですね。また、私の印象ですが実際のE資格試験はここまで問題が洗練されていないため、Amazonの書評にある「参考書の内容とテストの内容が擦りもしない印象です。」というのはあながち間違いではないかも知れません。
しかし、私はシラバスの範囲の各項目の理解を深めるのに有効だと思いましたので、敢えてお薦め本に挙げさせてもらいました。因みに私の場合、この黒本を何度も繰り返し解いて各項目の理解を深めました。ただし、E試験対策としては、寧ろAvilenさんが講座修了者に解放しているオンライン演習問題を何度も行う方が良かったとは思います。
その他の参考図書
さて、ここからはお薦め本までではないですが、参考図書としていくつか挙げたいと思います。
まず、GANの発明者による深層学習を網羅的に解説した書籍です。
")
- 発売日: 2018/08/27
- メディア: Kindle版
JDLA理事長の東大の松尾先生監修で東大の学生により翻訳がなされており、目次や中身をざっと見るとE資格試験のシラバスの元になっているように思えます。実際にこの書籍から問題が出ることもあるようです。ただし、もともと理解が難しい内容について、本がカバーしている範囲が広く、したがって、説明が簡潔すぎ、分かりにくいことに加えて、Amazonの書評にもある通り日本語訳に難があり、私は読み進めるのを途中で諦めました。Avilenさんの演習問題で背景が良く分からないものが出てきた時に、辞書的に参照するような使い方をしていました。ちょっと高いですし、購入まではなかなかお勧めはできないかも。英語が問題ない方でしたら、以下のサイトでオリジナル本の内容が無料で公開されていますので参考にしてください。
Deep Learning - An MIT Press book
⑤Pythonではじめる機械学習 ―scikit-learnで学ぶ特徴量エンジニアリングと機械学習の基礎

Pythonではじめる機械学習 ―scikit-learnで学ぶ特徴量エンジニアリングと機械学習の基礎
- 作者:Andreas C. Muller,Sarah Guido
- 発売日: 2017/05/25
- メディア: 単行本(ソフトカバー)
E資格試験対策には直接には結びつかないかも知れませんが、scikit-learnを使ってコードを描きながら読み進めれば、scikit-learnを用いた機械学習を一通り学習・理解できるようになります。ディープラーニング以外の機械学習を理解する助けにはなると思います。
⑥Rによる 統計的学習入門

- 作者:Gareth James,Daniela Witten,Trevor Hastie,Robert Tibshirani
- 発売日: 2018/08/03
- メディア: 単行本(ソフトカバー)
Amazonの書評にも書かれていますが、「米国でロングセラーになっている大学生向けの機械学習の教科書」のようです。機械学習(ディープラーニングを除く)について、数式を最小限に抑えながら、理論面から説明を行なっています。ディープラーニング以外の機械学習の理解に役に立つと思います。ただし、日本語版は高いため、私は無料で公開されているオリジナルを読みました(E資格に挑戦する前に読んでましたので、時間に余裕があったので、オリジナルを読むことができました)。
An Introduction to Statistical Learning
表題に「Rによる」とありますが、各章末の練習問題がRを使ったものになっているだけで、内容そのものはプログラム言語に依存していませんので、Rが分からなくても問題ないかと思います。
⑦線形代数キャンパスゼミ

- 作者:馬場 敬之
- 発売日: 2020/07/21
- メディア: 文庫
大学時代はきちんと勉強していなかったため、すっかり忘れていましたので、こちらで一通り勉強しました。短期間でキャッチアップ、あるいは勉強するためにはお薦めです。ただし、シラバスに含まれている特異値分解はカバーされていませんので、別のもので勉強する必要があります。幸い、YouTubeで解説されている方の動画がありましたので、私はそこで特異値分解の概念を理解し、あとは黒本とAvilenさんのE資格試験例題の解説で繰り返し勉強しました。
勉強の方法
どのように勉強したかについて、以下、整理します。
①JDLA認定講座の受講(2020/10〜12)
- Avilenさんの講座はしっかりしているので、この間は講座の受講を中心に据えて勉強しました。また、講座は大きく6つの分野に分けて提供されており、その各分野の講義終了後には、コーディング演習が課題として設定されており、それがなかなか考えさせるもので、良くできていると思います。
- そういう意味で、理解を深めるために、また、コーディング課題を克服するために、①ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装と②ゼロから作るDeep Learning ―自然言語処理編を勉強しました。また、その後、疑問点が出るたびに、何度も読み返しました。加えて、概念的に理解が難しい、im2col等のアルゴリズムについては、ネットで検索し、理解が深まるサイトをいくつか参照しながら、理解を深めようとしました。
- さらに、線形代数等の基本的な分野については、⑦線形代数キャンパスゼミで大学卒業以降すっかり忘れていたことを復習しました。また、そこでカバーされていない特異値分解についてはYouTube等で基本的な概念の理解に努めました。
- 加えて、最後にプロダクト開発演習がありましたので、テーマにはその時点で掘り下げた理解が不足していたNLP分野をテーマとして選び、BERT等理解が不足していた分野については別途ネットで情報を入手する等して課題に取り組みました。
②JDLA認定講座修了後(2021/1〜試験直前)
- 知識の定着化を目標に据えて、Avilenさんのオンラインで提供される演習問題を繰り返し受けたほか、Avilenさんの模試と所謂「黒本」を繰り返し解きました。また、JDLAが認定プログラム提供業者経由で開示しているJDLAの例題についても何度も解きました。
- Transformerだったり、Bertだったり、MobileNetだったり、モデルの理解を深める必要があると考えたものについては、オリジナル論文をプリントアウトし、読むようにしました。各論文ともそれほどページ数が多くなく、また、ネット等の記事等では間違いもありますので、オリジナルを確認する必要性についてはかなり感じましたね。特にFaster RNN、YoloやSSD、Unet当たりは一部ネット記事や例題などに混乱が見られたので、ぜひオリジナルの論文を参照いただいた方が良いかもしれません。
以上です。繰り返しになりますが、特に直前期は集中的に何度も繰り返し勉強しました。今後E資格を受験される方のご参考になれば幸いです。
React HooksとDjango REST Frameworkを使ってTo Do Listを作ってみた(後編)〜バックエンド編
前回に引き続き、React(フロントエンド)+Django(バックエンド)によるTo Do Listアプリを作っていきます。
今回はバックエンド編です。
環境構築
Djangoを利用しますので、任意の名前の仮想環境を構築しておきます。
当該仮想環境を立ち上げて、以下をインストールします。
pip install django pip install djangorestframework pip install django-cors-headers
djangorestframeworkはDjango REST Frameworkを利用するためのもので、django-cors-headersは、ReactアプリのアドレスとDjangoのアドレスが異なっているため、通常ではブラウザは通信できません。ReactアプリとDjangoが適切にAPI通信を行うために必要なモジュールとなります。
私の環境における各バージョンは以下の通りです。
Django 3.0 djangorestframework 3.11.1 django-cors-headers 3.4.0
Djangoの設定
Django プロジェクト及びアプリの作成
まずは、Djangoプロジェクトを作成します。任意のプロジェクト名をつけますが、ここではtodoprojとしています。
そしてtodoprojフォルダに移動し、そこでdjangoアプリを作成します。ここではアプリ名をtodoappとしています。
django-admin startproject todoproj cd todoproj python manage.py startapp todoapp
settings.pyの設定
todoprojフォルダ傘下のsettings.pyを以下の通り修正します。
INSTALLED_APPS = [
...
'rest_framework', # <- 追加
'corsheaders', # <- 追加
'todoapp.apps.TodoappConfig' # <- todoappを追加
]
## django-cors-headersを利用する場合
MIDDLEWARE = [
'corsheaders.middleware.CorsMiddleware',
'django.middleware.common.CommonMiddleware',
.....
]
# Djangoが通信する相手であるReactアプリのポートを指定
CORS_ORIGIN_WHITELIST = [
'http://localhost:3000'
]
Djangoアプリの書き方
それでは、Django REST Frameworkを利用したアプリを具体的に記述していきます。
モデル(models.py)
Django REST Frameworkを利用する場合であっても、このモデルの作成は通常のDjangoと同様となります。したがって、models.pyにdjango.db.models.Modelを継承したクラスとして定義します。
Reactアプリで使っているfieldをここで定義します。idはReact側でuuidを自動的に付与しますので、ここではCharField(文字列)とします。また、primary_key=Trueとしないとmakemigration時に警告が出てきます。その他titleを文字列としてisCompletedをBool値として設定します。
from django.db import models class Task(models.Model): id = models.CharField(max_length=128, primary_key=True) title = models.CharField(max_length=256) isCompleted = models.BooleanField(default=False) def __str__(self): return self.title
シリアライザ(serializers.py)
シリアライザは、データを保持しておくための入れ物で、JSON文字列とモデルオブジェクトの相互変換をしてくれるものです(「現場で使えるDjango REST Frameworkの教科書」)。
今回は、Taskモデルでの定義に基づき、JSONの入出力が行われるため、ModelSerializerを継承したシリアライザを利用することができます。これにより、モデルのフィールド定義が内部的に再利用されるため、このsirializers.pyでの記述が非常に簡単になります。
具体的には以下の通り。
from rest_framework import serializers from .models import Task class TaskSerializer(serializers.ModelSerializer): class Meta: model = Task fields = ['id', 'title', 'isCompleted']
ビュー(views.py)
このビューの役割は、JSONデータが入ったリクエストオブジェクトを受け取り、APIの種類に応じた処理を実行し、JSON形式のレスポンスオブジェクトを返すことです。
今回のモデルは、Taskのみの単一モデルなので、ModelViewSetを利用すれば、CRUDを処理するAPIを簡単に実装することができます。
具体的には、views.pyを以下のとおり最低限記述するだけで利用可能ととなります。
from rest_framework import viewsets from .serializers import TaskSerializer from .models import Task class TaskViewSet(viewsets.ModelViewSet): queryset = Task.objects.all() serializer_class = TaskSerializer
URLconf(Urls.py)
URLconfとはURLのパターンの集まりで、適切なビューを見つけるために、DjangoがリクエストされたURLと照合するものです。
API用のURLパターンを新たに設定する場合、通常のDjangoと同様にurlpatternsリストにpath関数等を利用して、URLパターンとビューのセットを記載します。
# todoproj/settings.py from django.contrib import admin from django.urls import path, include urlpatterns = [ path('admin/', admin.site.urls), path('api/', include('todoapp.urls'))
なお、ModelViewSetを継承した場合には、Django REST Framework独自のRouterクラスを使って設定します。
# todoapp/settings.py from django.urls import path, include from rest_framework import routers from .views import TaskViewSet router = routers.DefaultRouter() router.register('tasks', TaskViewSet) urlpatterns = [ path('', include(router.urls)) ]
これでdjangoを起動して、ブラウザのアドレスバーにhttp://127.0.0.1:8000/api/tasksを入力すると、ブラウザ上にtasks(task一覧)が表示されるようになります。
なお、DjangoのAdmin管理画面でTaskの登録状況が一応見られるように、以下のとおり登録しておきます。
from django.contrib import admin from .models import Task admin.register(Task)
以上で準備は完了です。
それでは、仮想環境になっていることを確認して、python manage.py rumserverで Djangoを起動させます。
そしてアドレスバーにhttp://127.0.0.1:8000/api/tasksを入力すると以下の画面が立ち上がりました。まだ、データは登録していないので、ブランクリストが表示されていますね。
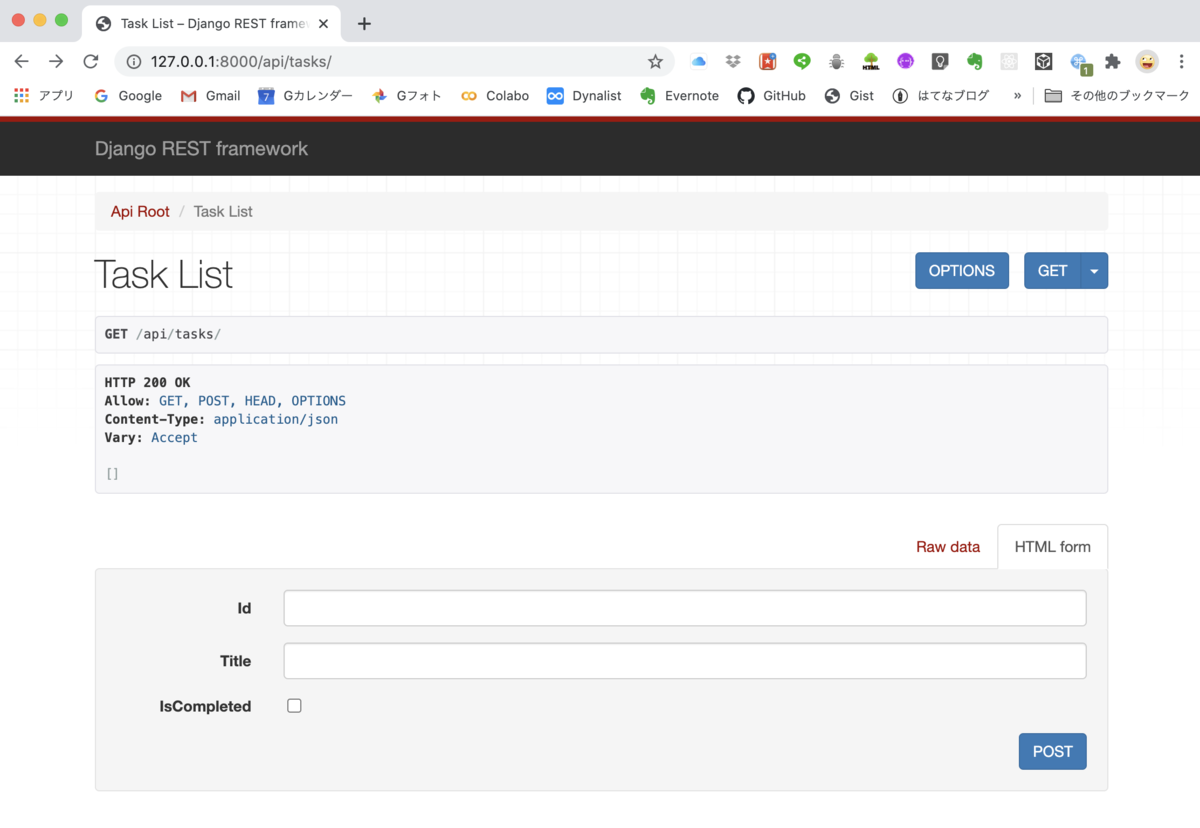
データをいくつか登録しておきましょう。
下側のhtml formの記載のあるボックスに「id」「title」「isCompleted」が入力できるようになっているので、適当に入力してPOSTを押すと登録できます。
idは文字列で他のtaskと重ならないように以下のとおり入力してみました。
id: a001
title: Reactを学習する
isCompleted: チェック
id: a002
title: お米を買う
isCompleted: チェックしない
id: a003
title: お酒を買う
isCompleted: チェックをしない
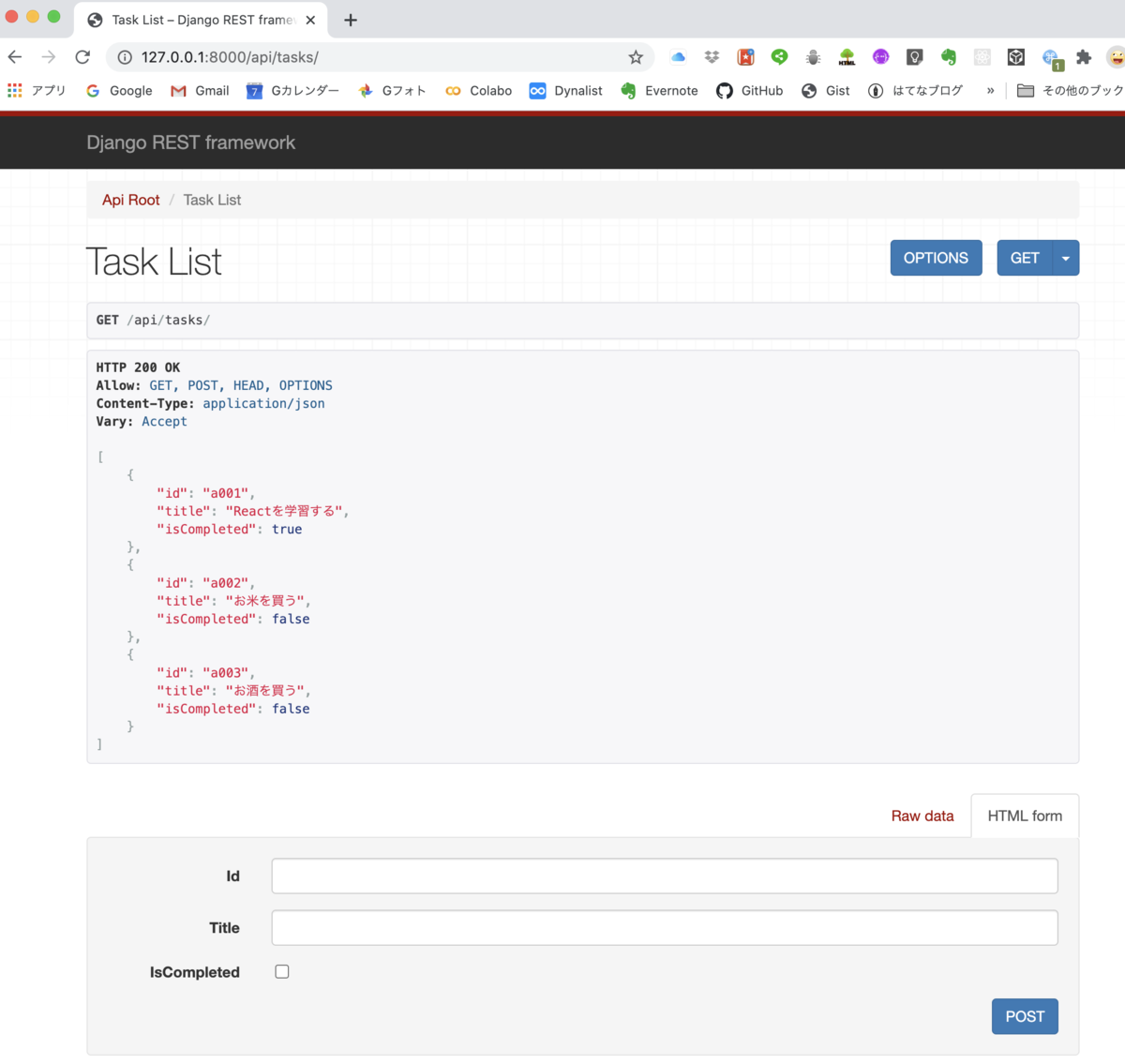
上段のボックスのGET をクリックします。すると以下のとおり、Task Listが表示されました。
なお、入力済みの個別taskの修正や削除を行いたい場合は、アドレスバーに http://127.0.0.1:8000/api/tasks/a001と最後にidを入力します。すると以下のとおり、個別明細とPUTやDELETE表示が出ますので、適宜修正や削除が可能です。
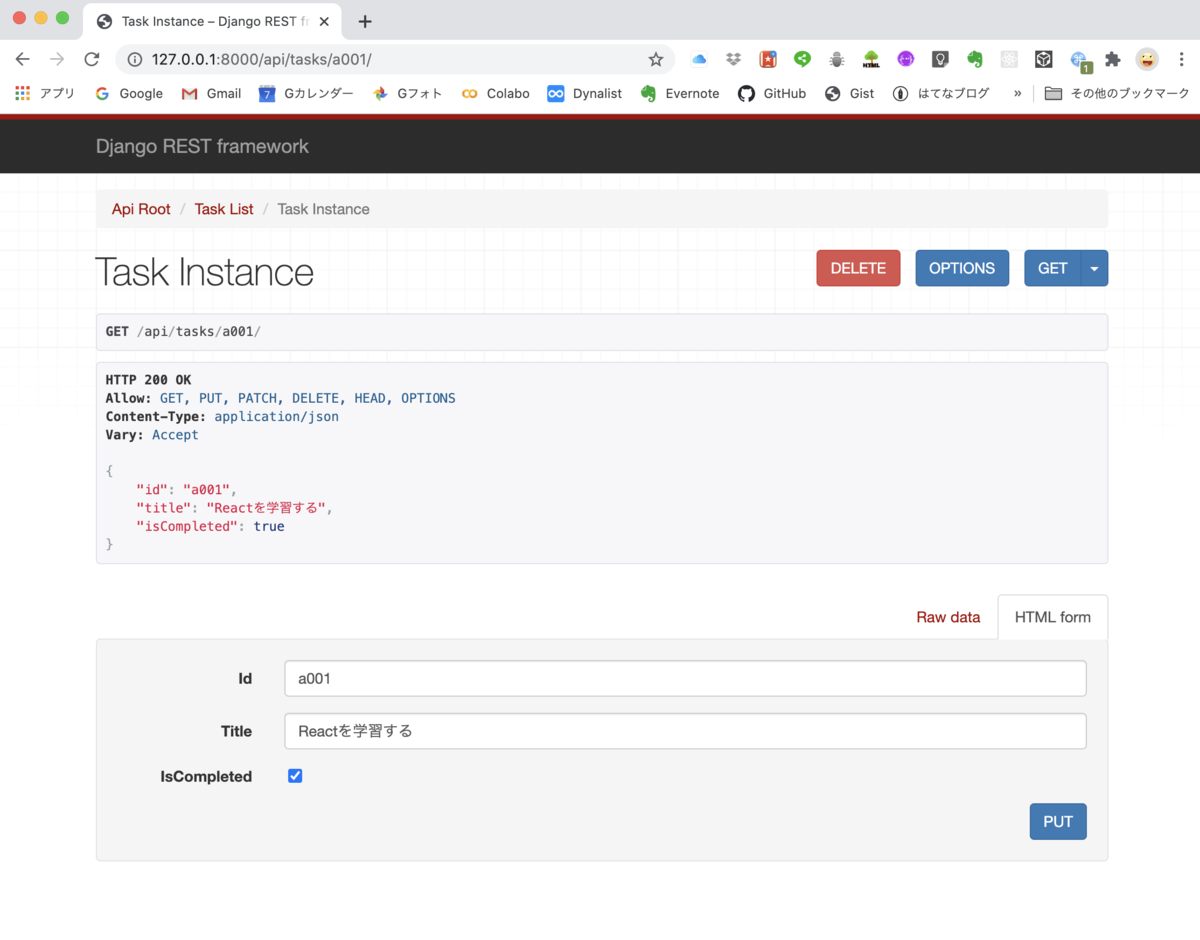
ここでは、「学習する」を「勉強する」に修正しておきました。
Reactアプリと繋げる
さて、いよいよReactアプリとDjangoを接続します。まずはReactアプリを修正して、json-serverではなく、Djangoに接続できるように設定します。
Reactアプリの修正
baseUrlを以下のとおり修正します。
細かいところですが、addの場合とupdateの場合には、${baseUrl}/や${baseUrl}/${id}/と最後に/をつけないとエラーとなってしまいます。
import axios from 'axios'; // const baseUrl = "http://localhost:3001/tasks"; const baseUrl = "http://localhost:8000/api/tasks"; async function getAll () { const response = await axios.get(baseUrl); return response.data; } async function add (newTask) { const response = await axios.post(`${baseUrl}/`, newTask) return response.data; } async function update(id, updatedTask) { const response = await axios.put(`${baseUrl}/${id}/`, updatedTask) return response.data; } async function _delete(id) { await axios.delete(`${baseUrl}/${id}`); return id; } export default { getAll, add, update, delete: _delete }
これで準備が整いました。
React アプリのあるフォルダ(ここではmytodo)に移動し、npm startでアプリを立ち上げます。
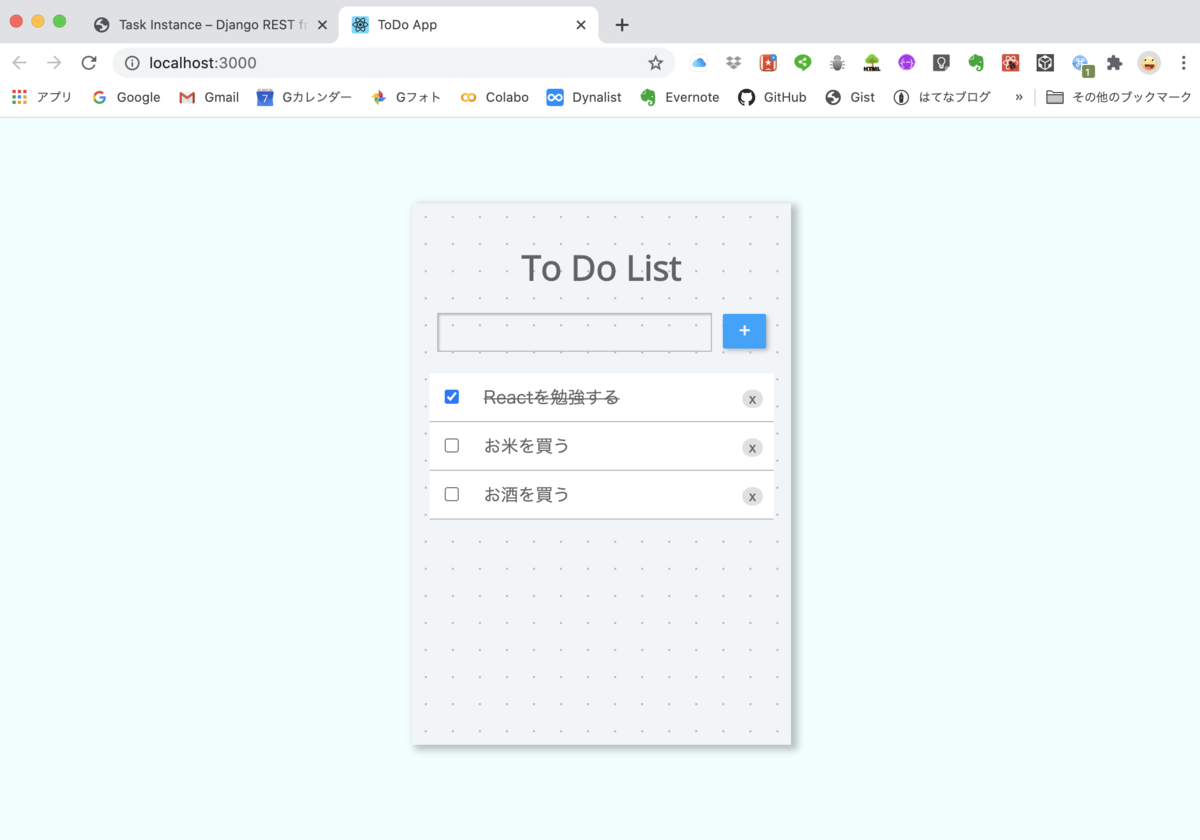
無事にDjangoと接続できました。
djangoプロジェクトのtodoprojの下にfrontendというフォルダを作成し、その下にmytodoを移動しておくと、djangoとの関係性が明確で良いかと思います。
今回は単純なアプリでしたが、それでもHooksの概念がなかなか理解できず(副作用って一体何?だったり、Hooksの種類がいろいろあったりで)、手間取ったところもありましたが、何とかイメージしたことは実装できました。
今後は、ユーザー登録機能だったり、順番を入れ替える、期日管理を行うなど実装にチャレンジしたいなとは思っています。ただ、やりたいことが結構増えてしまっていますので、いつになるか分かりませんが...
React HooksとDjango REST Frameworkを使ってTo Do Listを作ってみた(前編)〜フロントエンド編
最近気に入って使っているDashなんですが、React.jsというJavaScriptのライブラリをベースにしていると開発元のホームページに書いてあります。
また、Dashのグラフコンポーネントを新たに作るならReactを学ぶことが勧められています。
さらに、こちらのページによるとJavaScriptのフロントエンドフレームワークの中で最も世界的に人気があるようで、Googleトレンドでも同様の結果となっています。
これらにそそのかされて、この1ヶ月程、Reactを集中的に学んでみました(JavaScriptの再学習も併せて)。そこで、自分自身の理解を深めるために、ReactでTo Do Listアプリを作成してみましたので、紹介したいと思います。
なお、Djangoをバックエンドとして使いたいと思っていろいろなサイトを見てみましたが、Django REST Frameworkを使っているサイトが多いようなので、今回Django REST Frameworkを利用することにしました。
出来上がりはこんな感じ。
まずは、フロントエンドを、Reactを使って、To Do LIstアプリを作成(データベースとしてはjson-serverを利用)。その後、Django REST Frameworkを使ってバックエンドを作成し、一旦作成したReactと繋げていきます。
Reactのインストール(Mac)
1. node.jsをインストール
こちらのサイトからNode.jsのLTS版をインストールします。
nodejs.org
Node.jsはJavaScriptで作られているバックエンドのフレームワークです。今回はNode.jsをインストールすると、同時にインストールされるnpm(Node Package Manager: Node.jsのパッケージを管理するツール)を利用します。
2. 新たにReactアプリを作成
1により Node >= 8.10 及び npm >= 5.6 がインストールされているので、新たにReactプロジェクトを作成するには以下をターミナルから実行するだけです。mytodoのところは任意のアプリ名を入れます。
npx create-react-app mytodo cd mytodo npm start
ここでReactアプリが立ち上がるはずが、以下のような表示が出て先に進めなくなってしまうことが環境によっては良くあります。私の場合がそうです。
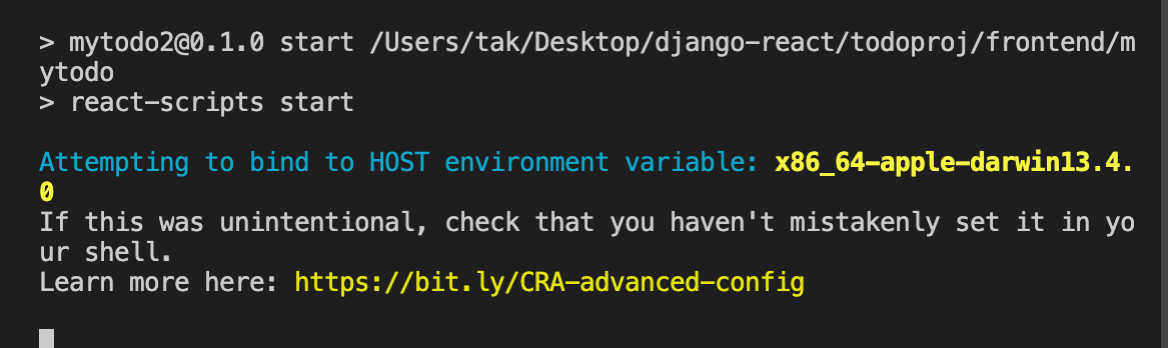
この場合は一旦ctr+cにて中断して、ターミナルにて
unset HOST
を入力し、Enterキーを押します(HOST情報の解除)。これで再度npm startにてReactアプリ(初期画面)が立ち上がるようになります。
必要なパッケージのインストール
今回インストールするパッケージとその役割は以下の通り。
- json-server:Reactから利用できる簡易サーバー(モックアップサーバーというらしい)です。まずはフロントエンドで完結できるよう、このサーバーとjsonデータをやりとりできるようにします。
- axios:モックアップサーバーとの通信に利用する非同期通信ライブラリです。
- uuid:一意なIDを生成するライブラリで、各TaskのIDの作成に利用します。
インストールは、先ほどのmytodo直下で以下のコマンドを入力して行います。
npm install --save-dev json-server npm install axis npm install uuid
モックアップサーバーの設定
初期データの準備
mytodoフォルダ直下にdb.jsonというJSONファイルを追加し、以下を記述します。
{ "tasks": [ { "id": "f543f73d-48d6-4b65-a07f-20cf68e11461", "title": "TO DO LISTをReactで作成する", "isCompleted": false }, { "id": "9e25ddb3-ac4a-4354-9320-d8211762d1fb", "title": "お米を買う", "isCompleted": false }, { "id": "6a18845a-c537-4263-8cc7-9e62b96d90ee", "title": "お酒を買う", "isCompleted": false } ] }
これがモックアップサーバー上のデータになります。idは取り敢えず何でも大丈夫です。新規で追加される場合には、uuidにより自動的にidが付加されます。
モックアップサーバーの起動準備
mytodoフォルダ直下にあるpackage.jsonの中にあるscriptsセクションに以下のとおり、json-serverに関する設定を追加します。
"scripts": { "start": "react-scripts start", "build": "react-scripts build", "test": "react-scripts test", "eject": "react-scripts eject", "server": "json-server --watch db.json --port 3001" // 追加 },
これにより、ターミナルからnpm run serverというコマンドを入力すれば、モックアップサーバーが立ち上がります。なお、npm startで立ち上がるReactアプリのポートが3000のため、モックアップサーバーのポートを--port 3001と3001に設定しています。--watch db.jsonにてjson-serverが常にdb.jsonの変更を監視できるように設定しています。
モックアップサーバーの起動確認
ターミナルにてnpm run serverと入力するとモックアップサーバーが立ち上がります。ここで、任意のブラウザにてhttp://localhost:3001/tasksにアクセスすると画面にdb.jsonに登録したデータが表示されます。
To Do Listアプリの作成
こちらのサイトなどを参考にしながらTo Do Listアプリを作成しました。
ファイル構成
ファイル構成は以下の通りです。npx create-react-appでインストールされるファイルで不要なものは削除しています。
public/
index.html
style.css
src/
index.js
App.js
api/
TaskApi.js
components/
Task.js
TaskForm.js
TaskList.js
TaskProvider.js
node_modules/
db.json
package.json
package-lock.json
ファイルの内容
このアプリでは、React Hooksのうち、基本フックであるuseState, useContext及びuseEffectを利用しています。
useStateは基本のHookになります。Reactのオフィシャルページによると以下のとおり。
useState は現在の state の値と、それを更新するための関数とをペアにして返します。この関数はイベントハンドラやその他の場所から呼び出すことができます。
要は、コンポーネントの中でデータを保持し、関数を使ってそのデータを加工できる仕組みをいいます。
また、useContextは、オフィシャルページでは以下のとおり。
コンテクストオブジェクト(React.createContext からの戻り値)を受け取り、そのコンテクストの現在値を返します。コンテクストの現在値は、ツリー内でこのフックを呼んだコンポーネントの直近にある <MyContext.Provider> の value の値によって決定されます。
何を言っているか良くわかりませんねぇ。
いろいろ調べてみると、このフックを利用すれば、親コンポーネントから子コンポーネントにデータを渡す際に使うPropsを利用しなくても良くなります。加えて「親から子にPropsを渡し、さらにその子供にPropsを渡し、さらにその子供に...」といったPropsのバケツリレーを行う必要がなくなり、どのコンポーネントからでもデータにアクセスできるようにするためのフックです。
useEffectは、オフィシャルページは分かりにくいので、以下のとおり整理しました。
コンポーネントに副作用のある命令型コード(side effect)を追加するフックをいう。 副作用のある命令型コード(side effect)とは次のような処理を実行する関数のこと。これらは関数コンポーネント本体で書くことはできない(バグや非整合性の原因)。
- DOMの変更
- APIとの通信
- 非同期処理
- タイマー
- console.log(ロギング)
代わりに、useEffectを利用する。useEffectに渡された関数は、レンダーの結果が画面に反映された後に動作する(デフォルト)。特定の値が変化した時のみ動作させることも可能。
最初にuseState,useContext, useEffectの全てを利用している本アプリの肝であるTaskProvider.jsについて説明します。
TaskProvider.js
// 1. 各ライブラリから必要なモジュールのインポート import React, { useState, useEffect, useContext, createContext } from 'react'; import { v4 } from 'uuid'; import TaskApi from '../api/TaskApi'; // 2. Contextオブジェクトとカスタムフック const TaskContext = createContext(); const useTasks = () => useContext(TaskContext); function TaskProvider({ children }) { // 3. useStateの設定 const [tasks, setTasks] = useState([]); // 4. 当初レンダリング時のデータ取得 useEffect(() => { TaskApi.getAll().then(tasks => { setTasks(tasks); }); }, []) // 5. タスクの追加 const addTask = item => { const newTask = { id: v4(), title: item, isCompleted: false } TaskApi.add(newTask).then(addedTask => ( setTasks([...tasks, addedTask]) )) } // 6. データステータスの変更 const toggleStatus = (id, status) => { const item = tasks.find(task => task.id === id) const updatedTask = {...item, isCompleted: status} TaskApi.update(id, updatedTask).then(newTask => { const newTasks = tasks.map(item => item.id === newTask.id ? newTask : item); setTasks(newTasks); }) } // 7. データの削除 const deleteTask = id => { TaskApi.delete(id).then(deletedId => { const newTasks = tasks.filter(item => item.id !== deletedId) setTasks(newTasks); }) } // 8. リターン値 return ( <TaskContext.Provider value={{ tasks, addTask, toggleStatus, deleteTask }}> { children } </TaskContext.Provider> ) } export default TaskProvider; export { useTasks }
1.各ライブラリから必要なモジュール(関数、オブジェクト等)のインポート
まず最初にReact及び2つのHooks(useStateとuseContext)をインポートします。createContextはuseContextを利用するために必要ですので、併せてインポートしておきます。また、新たにTaskを追加した際に、自動的に一意のidを追加するため、uuidライブラリからv4モジュールをインポートします。
2.Contextオブジェクトとカスタムフック
createContextにてContextオブジェクトを生成し、TaskContextとします。このTaskContextを呼び出す(useContext)を関数の形でカスタムフックuseTasksとして定義します。これにより、どのコンポーネントにおいても、tasksアレイや必要な関数(以降で定義)にアクセスできるようになります。
3.useStateの設定
useState Hookにより、taskアレイを初期化し、デフォルト値として空のアレイを設定します。このuseStateは2つのオブジェクトのアレイを返します。1つは状態を表す値(taskアレイ)とその値を変更するのに使う関数(setTasks)です。
当初レンダリング時に、モックアップサーバーからAPIによりデータを取得します。APIとの通信は副作用(side-effect)に該当しますので、useEffectを利用する必要があります。第二引数に[]と指定していますので、当初レンダリング時にのみデータを取得します。
データを取得後、setTasks(tasks)にて、tasksアレイに取得データを設定しています。
5.タスクの追加
ここでaddTask関数を作成しており、他のコンポーネントでもタスクを追加することができます。タスクのタイトルを入力すると、v4により自動的にユニークなidと、完了フラグisCompletedがfalseに設定されます(newTask)。APIにより、json-serverにnewTaskとして登録した後、setTasksにより、...task(スプレッド構文)で展開される既存taskアレイに、newTaskを追加してtasksに登録します。
6.データステータスの変更
ここでは、toggleStatus関数を作成しています。チェックボックス のオンオフをstatusとして与えた時に、その対象となっているtaskのisCompleteの値(true/false)を変更するようにしています。json-severのデータを書き換えた後に、setTasksによりtaskアレイも変更します。
7.データの削除
ここで、deleteTask関数を作成しています。対象タスクのidを与え、json-serverのデータを削除し、また、taskアレイも変更しています。
8.リターン値
2にて定義したTaskContextを<TaskContext.Provider value={{}}>{children}</TaskContext.Provider>の形でchildren
(子コンポーネント)を挟んでリターン値として返すことで、コンポーネント間でこのvalueを共有できます。
TaskApi.js
次はTaskApi.jsです。これはaxiosライブラリを利用してjson-serverとデータのやりとりを行うスクリプトファイルです。
GitHub - axios/axios: Promise based HTTP client for the browser and node.js
axiosはエラー発生時のハンドリングのロジック等を追加できますが、ここでは、そうしたロジックを記述せずに単純にaxios.getでデータの取得、axios.postでデータの追加、axios.putでデータの修正、axios.deleteでデータの削除を行っています。
import axios from 'axios'; const baseUrl = "http://localhost:3001/tasks"; async function getAll () { const response = await axios.get(baseUrl); return response.data; } async function add (newTask) { const response = await axios.post(baseUrl, newTask) return response.data; } async function update(id, updatedTask) { const response = await axios.put(`${baseUrl}/${id}`, updatedTask) return response.data; } async function _delete(id) { await axios.delete(`${baseUrl}/${id}`); return id; } export default { getAll, add, update, delete: _delete }
以降は、上位のファイルの内容から順に記載していきます。
index.js
このファイルは、index.htmlの<div id="root"></div>タグに紐つけ、<App />(Appコンポーネント)を表示させる役割を持っています。
<React.StrictMode>は、公式HP↓にも記載されていますが、strictモードの設定で、開発環境のみ有効な機能です。例えば、React Hooksを安全でない使い方をした場合に、警告メッセージが出力されるようになります。
<TaskProvider>は最初に説明したコンポーネントです。この間に挟まれた<App />以降のコンポーネント間でTaskProvider.jsにおいて設定されているvalueであるtasksアレイ, addTask・toggleTask・deleteTask間をuseTasksを通じて共有できるようにしています。
import React from 'react'; import ReactDOM from 'react-dom'; import App from './App'; import TaskProvider from './components/TaskProvider'; ReactDOM.render( <React.StrictMode> <TaskProvider> <App /> </TaskProvider> </React.StrictMode>, document.getElementById('root') );
App.js
このファイルは、タイトル(h1タグ)と2つのコンポーネント<TaskForm />及び`
import React from 'react'; import TaskForm from './components/TaskForm'; import TaskList from './components/TaskList'; function App() { return ( <div className="container"> <h1 className="title">To Do List</h1> <TaskForm /> <TaskList /> </div> ); } export default App;
TaskList.js
ここでは、useTasks'によりtasksアレイのみ取り出して、map`メソッドによりTaskコンポーネントを展開しています。
import React from 'react'; import Task from './Task'; import { useTasks } from './TaskProvider'; function TaskList() { const { tasks } = useTasks(); return ( <table> <tbody> { tasks.map((task, id) => <Task key={id} {...task} /> ) } </tbody> </table> ) } export default TaskList;
Task.js
Taskコンポーネントを定義しています。カスタムフックuseTasksを通じて、toggleStatus関数とdeleteTask関数を取り出しています。それぞれチェックボックス のオンオフ、xボタンのクリックに対応させています。また、チェックボックス をオンにすると、titleに取消線(line-through)が表示されるようにしています。
import React from 'react'; import { useTasks } from './TaskProvider'; function Task({ id, title, isCompleted }) { const { toggleStatus, deleteTask } = useTasks(); const checkTask = event => toggleStatus(id, event.target.checked); return ( <tr> <td> <input type="checkbox" onChange={checkTask} checked={isCompleted} /> </td> <td className="align-left" style={{width: "100%"}}> <span style={{textDecoration: isCompleted && "line-through"}}> {title} </span> </td> <td> <button onClick={() => deleteTask(id)}>x</button> </td> </tr> ) } export default Task;
TaskForm.js
フォーム入力のためのコンポーネントです。useTasksを通じてaddTask関数を利用できるようにしており、+ボタンを押すとその時点で入力していたタスクが追加されます。
import React, { useState } from 'react'; import { useTasks } from './TaskProvider'; function TaskForm() { const [task, setTask] = useState('') const { addTask } = useTasks(); const submit = event => { event.preventDefault(); addTask(task); setTask(''); } return ( <form onSubmit={submit}> <input type="text" value={task} placeholder="" onChange={event => setTask(event.target.value)} required /> <button>+</button> </form> ) } export default TaskForm
説明は以上です。
今回設定したcssは以下の通りです。
/* style.css */ body { background-color: azure; min-height: 70vh; padding: 1rem; box-sizing: border-box; display: flex; justify-content: center; align-items: center; color:rgb(99, 99, 99); text-align: center; font-size: 100%; } .container { width: 100%; height: auto; min-height: 500px; max-width: 500px; min-width: 350px; background: #f1f5f8; background-image: radial-gradient(#bfc0c1 7.2%, transparent 0); background-size: 25px 25px; box-shadow: 4px 3px 7px 2px #00000040; padding: 1rem; box-sizing: border-box; } form input { box-sizing: border-box; background-color: transparent; padding: 0.5rem; font-size: 1rem; border: 1px solid rgb(185, 185, 185); box-shadow: 1px 1px 2px rgb(185, 185, 185) inset; width: 80%; margin-bottom: 20px; } form button { color: rgb(245, 245, 245); font-size: 1.2rem; width: 40px; height: 32px; border: none; background-color: rgb(0, 162, 255); border-radius: 5%; margin-left: 10px; box-shadow: 2px 2px 4px rgb(185, 185, 185); } table { border-spacing: 0; } table td { border-bottom: solid 1px rgb(185, 185, 185); background-color: white; padding: 10px; } td button { color: rgb(104, 104, 104); border: none; background-color: rgb(224, 224, 224); border-radius: 100%; } .title { font-family: 'Open Sans', sans-serif; } .align-left { text-align: left; }
動かしてみましょう
まず、ターミナルからnpm run serverにてjson-serverを稼働させます。
> mytodo2@0.1.0 server /Users/tak/Desktop/react/mytodo2
> json-server --watch db.json --port 3001
\{^_^}/ hi!
Loading db.json
Done
Resources
http://localhost:3001/tasks
Home
http://localhost:3001
Type s + enter at any time to create a snapshot of the database
Watching...
うまく立ち上がりました。
それでは別のターミナルからnpm startにてReactアプリを立ち上げます。
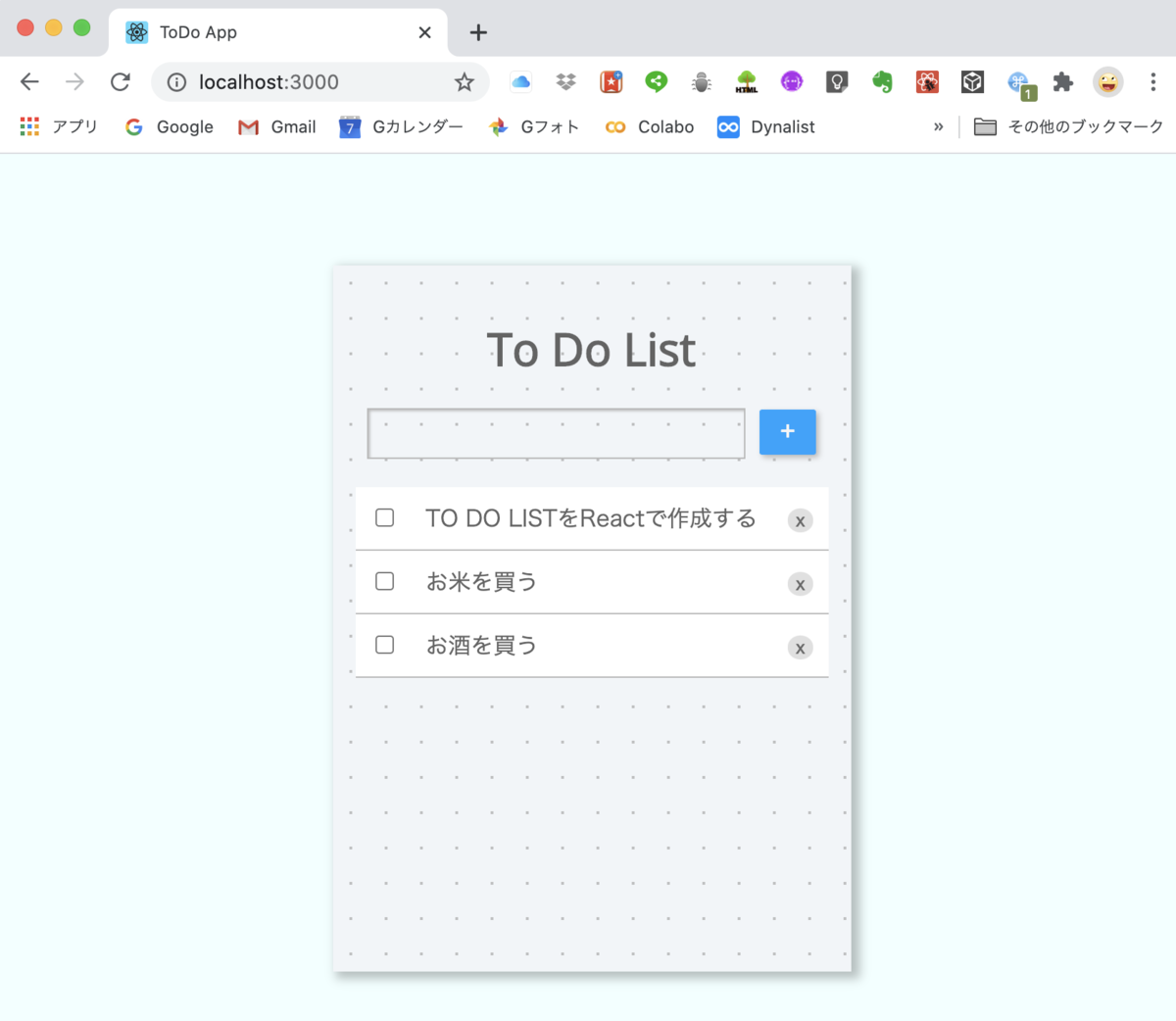
うまくいきました。
次回は、django REST frameworkを利用してバックエンドを作成し、今回作成したReactアプリとつなげたいと思います。
DjangoでDashとPlotlyのグラフを同時に描く
今回は、前回の「可視化フレームワークDashをDjangoで利用する」の続編です。Django上に作成したDashと同じページにplotlyで描いたグラフを追加するというものです。
plotly.js CDNを利用できるようにする
まずは、base.htmlにWebページでPlotly.jsを利用できるようにCDNの設定をしておきます。
<head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>World Map</title> <link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.5.0/css/bootstrap.min.css" integrity="sha384-9aIt2nRpC12Uk9gS9baDl411NQApFmC26EwAOH8WgZl5MYYxFfc+NcPb1dKGj7Sk" crossorigin="anonymous"> <!- ここを追加 -> <script src="https://cdn.plot.ly/plotly-latest.min.js"></script> </head>
views.pyに関数を記述する
前回のviews.pyは以下の通りでした。
# views.py(前回) def index(request): return render(request, 'worldmap/index.html')
今回は、ここに簡単な折れ線グラフを描く関数scatterを記述していきます。
# views.py(今回) def index(request): def scatter(): x1 = [1, 2, 3, 4] y1 = [30, 35, 25, 45] trace = go.Scatter( x = x1, y = y1 ) layout = dict( title = 'Simple Graph', xaxis = dict(range = [min(x1), max(x1)]), yaxis = dict(range = [min(y1), max(y1)]) ) fig = go.Figure(data=[trace], layout=layout) plotly_div = plot(fig, output_type='div', include_plotlyjs=False) return plotly_div context = { 'plot': scatter() } return render(request, 'worldmap/index.html', context=context)
ポイントはplot(fig, output_type='div', include_plotlyjs=False)のoutput_typeとinclude_plotlyjsかと思いますが、以下のサイトに詳しいのでそちらをご参照いただければと思います。
Plotlyで作るグラフをDjangoで使う - Qiita
contextにてscatter関数の結果をindex.htmlに渡します。
htmlページに結果を表示する
index.htmlに以下の記述を追記する。
{% extends 'base.html' %}
{% load static %}
{% block content %}
{% load plotly_dash %}
<div class="{% plotly_class name='WorldMap' %} card" style="height: 100%; width: 100%;">
{% plotly_app name='WorldMap' ratio=0.60 %}
</div>
<br>
{{ plot | safe}} <!- ここを追記 ->
{% endblock %}
あとは、前回 ratio = 1.0と利用可能画面の 100%をDashが占めるように設定していましたが、今回はこれを ratio = 0.65としてplotlyのグラフが表示できるように変更します。
これだけです。
それでは表示してみましょう。

画面下が切れているようですが、スクロールすると表示できます。 うまくいきましたね。
今回は以上です。
ご参考までに以下にスクリプトをアップしています。
GitHub - tak-akashi/djangomap2
可視化フレームワークDashをDjangoで利用する
前回、Dashを利用して世界統計地図を描いてみましたが、これだとシングルページなんですよね。
Dash自体はマルチページにも対応してしてます。が、今後、Webアプリケーションとして機能を拡張していくことを考えたら、DjangoでDashを利用できると良いですよね。
いろいろ調べたところ、django-plotly-dashというパッケージが良さそうということで、試してみました。一部、苦労しましたが、うまくいきましたので、紹介します。
django-plotly-dash — django-plotly-dash documentation
前回Dashにて描いた世界地図をDjangoに統合する例を説明していきます。
環境
- python==3.7.7
- Django== 3.0.8
- dash==1.11.0
- dash-bootstrap-components==0.10.3
- django-bootstrap4==2.2.0
以下は、世界銀行データからグラフを作成するのに使います。 - pandas==1.0.5
- world-bank-data==0.1.3
まずはDjangoのプロジェクト・アプリを設定しておく
django-admin startproject djangomap
任意のプロジェクト名(ここではdjangomap)にてDjangoプロジェクトを設定します。
このプロジェクト名のフォルダができるので、そのフォルダ下に移動し、アプリケーションを作成します。
ここではworldmapというアプリケーション名にしています。
python manage.py startapp worldmap
Django-plotly-dashをインストールする
pip install django_plotly_dash
ドキュメンテーションに従って、以下もインストールしておきます。
pip install channels daphne redis django-redis channels-redis
さらに以下もインストールします。
pip install dpd-components dpd-static-support
settings.pyの設定
settings.pyを変更していきます。まずは、インストールしたアプリケーションを利用できるように設定します。
# djangomap/settings.py INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'django_plotly_dash.apps.DjangoPlotlyDashConfig', # django-plotly-dashにより追加 'channels', # django_plotly_dashとともにchannelsをインストールしたため追加 'channels_redis', # django_plotly_dashとともにchannels_redisをインストールしたため追加 'bootstrap4', #django-bootstrap4を利用する場合 'worldmap.apps.WorldmapConfig' # 通常のdjangoアプリ設定に伴う追加 ]
続いて、以下を丸々、settings.pyの最後に追加します。
### django_plotly_dashにて追加(ここから) ### ASGI_APPLICATION = 'djangomap.routing.application' # djangomapのところにはプロジェクト名が入ります。 CHANNEL_LAYERS = { 'default':{ 'BACKEND': 'channels_redis.core.RedisChannelLayer', 'CONFIG': { 'hosts':[('127.0.0.1', 6379),], } } } STATICFILES_FINDERS = [ 'django.contrib.staticfiles.finders.FileSystemFinder', 'django.contrib.staticfiles.finders.AppDirectoriesFinder', 'django_plotly_dash.finders.DashAssetFinder', 'django_plotly_dash.finders.DashComponentFinder' ] PLOTLY_COMPONENTS = [ 'dash_core_components', 'dash_html_components', 'dash_renderer', 'dpd_components', 'dpd_static_support', 'dash_bootstrap_components', ] X_FRAME_OPTIONS = 'SAMEORIGIN' ### django_plotly_dashにて追加(ここまで) ###
urls.pyを修正(プロジェクトレベル)
プレジェクトレベル(ここではdjangomapフォルダ直下)の`urls.py'に以下を追加する。
urlpatterns = [
path('', include('worldmap.urls')),
path('admin/', admin.site.urls),
path('django_plotly_dash/', include('django_plotly_dash.urls')), # これを追加
]
routing.pyを追加
プロジェクトフォルダ直下にrouting.pyを追加します。
routing.pyには以下を記述します。
from channels.routing import ProtocolTypeRouter application = ProtocolTypeRouter({ })
Dashアプリの変更
前回作ったDashアプリを修正していきます。アプリケーションレベル(ここではworldmapフォルダ直下)に、dashアプリ
- import dashをfrom django_plotly_dash import DjangoDashに変更する
- dash.Dash(...)をDjangoDash('WorldMap', add_bootstrap_links=True)に変更する
- if name == "main":
app.run_server() を削除する
Dashアプリを表示するhtmlファイルを作成
アプリケーションレベル(ここではwouldmap直下)にtemplatesフォルダを作成、さらにworldmapフォルダを作成(Djangoの慣習)。そこに例えば、index.htmlを作成する(名前は任意)。そのファイルには以下の通り、記述する。
{% extends 'base.html' %}
{% block content %}
{% load plotly_dash %}
<div class="{% plotly_class name='WorldMap' %} card" style="height: 100%; width: 100%;">
{% plotly_app name='WorldMap' ratio=1.0 %}
</div>
{% endblock %}
順番が前後してしまいましたが、プロジェクトと同レベルにtemplatesフォルダを作成し、その中にbase.htmlを作成します。
そのbase.htmlには、ここではサンプルとして、Bootstrap4.3の以下のページの最初に出てくるNavbarをコピペして利用します。
views.pyとurls.py(アプリケーションレベル)
アプリケーションレベル(ここではworldmap)のviews.pyは通常通り。
# views.py from django.shortcuts import render def index(request): return render(request, 'worldmap/index.html')
urls.pyでは、Dashアプリをインポートしておく必要があります。
# urls.py from django.urls import path from . import views from . import worldmap # これが必要 app_name = 'worldmap' urlpatterns = [ path('', views.index, name='index') ]
これで設定できました。さて、migrateを忘れるとうまく動きません。
python manage.py migrate
を忘れずに。そして、以下で起動してみると。
python manage.py runserver
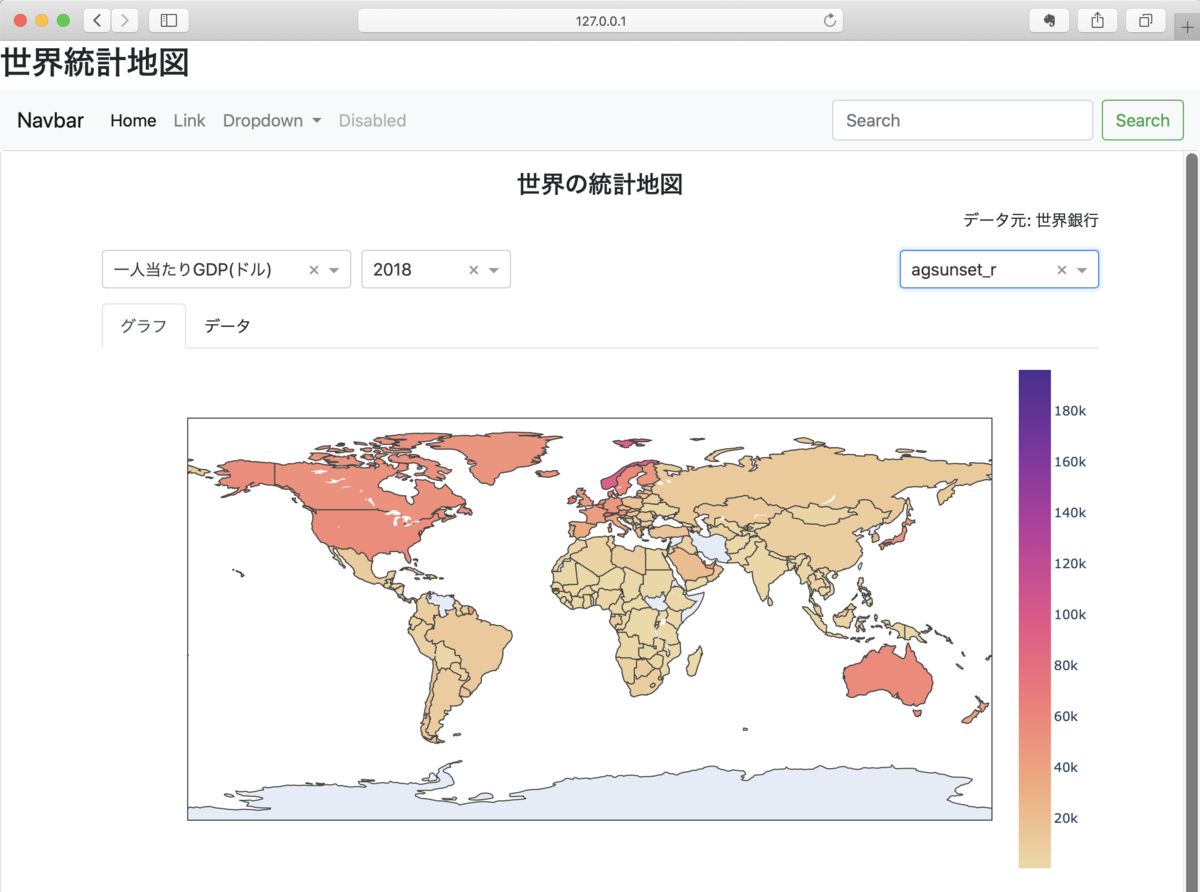
うまく行きました!
↓スクリプトはこちらにアップしておきました。
番外編
なお、上記の簡単な例をベースに、より機能強化を図ったサイトを作成し、Herokuにデプロイしましたので、こちらにもよろしければどうぞ。
可視化フレームワークDashで世界統計地図を描いてみた
Dashとはカナダに拠点をおくPlotly社が開発しているPythonから利用できるWebフレームワークで、様々なデータの可視化・グラフ化に利用できます。
以前紹介したPlotlyというPythonライブラリもこのDashで使えますし、Dashでは独自にグラフ化のためのコンポーネントを用意しているほか、htmlのタグ等もコンポーネント化していますので、簡単なWebページが作成できるというものです。Plotlyと同様にインタラクティブにグラフの操作が可能です。また、pandasのDataFrameを使えるのも良いですよね。
今回は、世界銀行が公表しているデータをworld_data_bankというライブラリを使って取得。このデータをDash上にグラフ化し、Herokuにデプロイしました。画面はこんな感じ。

サイトへのリンクはこちら↓
https://world-bank-map.herokuapp.com
左上のドロップダウンにて「一人当たりGDP(ドル)」「平均寿命」「人口」。隣のドロップダウンで「西暦年」を選択すると、グラフが表示されます。右のドロップダウンはDashで利用可能なカラーパレットです。いろいろなカラースケールを確かめたく、選択できるようにしてみました。また、グラフ表示だけでなく、タブでテーブルを選択するとグラフ表示で利用したデータをテーブル形式で見られるようにもしました。
世界銀行の公表データの取得
世界銀行(World Bank)は数多くのデータを公表していて、APIを利用して取得することができます。Pythonの場合、世界銀行のAPIを直接利用しなくても、このAPIを利用したモジュールがいくつかあります。
有名どころではpandas_datareaderを利用することができます。
pandas-datareader.readthedocs.io
今回は、公表データの一覧表等を比較的入手しやすいworld_bank_dataというモジュールを利用しました。
pypi.org
インストールは以下の通り。
pip install world_bank_data --upgrade
どんな感じのデータか見てみましょう。world_bank_dataとpandasをインポートしておきます。
import world_bank_data as wbd import pandas as pd
データを取得するには何のデータか特定する必要があります。World BankではIndicatorと呼んでいますが、こちらのサイトから検索できます。
Data Catalog | Data Catalog
あるいは、world_bank_dataのget_indicators()メソッドで全てのIndicatorを取得(17473 行!)して探すか、あるいはsearch_indicators('キーワード')で検索するかして、入手したいデータのindicatorを特定します。
今回は、「一人当たりGDP(ドル)」「平均寿命」「人口」を取得したいと思います。それぞれindicatorはNY.GDP.PCAP.KD, SP.DYN.LE00.IN, SP.POP.TOTLとなります。
get_series('インディケーター')メソッドで取得すると

MultiIndexのDataFrameが返されます。MultiIndexのうち、CountryとYearを軸にこれら3つのDataFrameをpandasのmergeを使って統合します。ついでに、indicatorをわかりやすい日本語に変えておきます。
_df = pd.merge(df_gdp_pcap,df_lifeexp, on=['Country', 'Year']) _df = pd.merge(_df, df_pops, on=['Country', 'Year']) _df.columns = ['一人当たりGDP(ドル)', '平均寿命(歳)', '人口(人)']

Dashのコロプレス図(choropleth map)を描くには、3文字の国コードが必要になります。幸いworld_bank_dataでは簡単に国・地域の一覧が入手できます。
df_all_countries = wbd.get_countries()
結果を見てみると、一番左のidが3文字の国コードですね。

これを先ほどの_dfと統合します。_dfのCountry欄とdf_all_countriesのname欄の紐つけています。
df = pd.merge(_df.reset_index(), df_all_countries.reset_index(), left_on='Country', right_on='name')

これだと、Country 欄にはまだ、国以外に地域(東アジア、ヨーロッパ等)が残っていますので、国だけのリストにします。ついでに、不要な欄を削除し、Year欄を文字列から整数列に変えておきます。
df = df[df['region'] != 'Aggregates'].reset_index(drop=True) df = df.drop(['iso2Code','name', 'adminregion', 'incomeLevel', 'lendingType', 'capitalCity', 'longitude','latitude'], axis=1).reset_index(drop=True) df['Year'] = df['Year'].astype(int)
Dashアプリを作成する
Dashについて、細かく説明するのは大変なので、省略します。すみません(笑)。詳しくは、本家の英語のTutorialを参照いただくか、日本語でチュートリアルを解説されているサイトをご参照いただければと思います。
ここではチュートリアルに書かれていないポイントを中心にいくつか記載します。
DashでBootstrapを利用する
今回タブを使っています。Dashにおいて標準で提供されているタブはdash_core_componentのTabなんですが、横に間延びしてしまって、格好が悪いんですよね。なので、dashでBootstrapを利用するためのモジュールであるdash_bootstrap_componentsをインストールして利用しています。
このdash_bootstrap_componentsのTabは、すっきりしていて良いのですが、標準では使わなくてよいcallback関数を使わないといけなくなるのが若干のマイナスポイントですかね。
コロプレス図はplotly.graph_objectsを利用する
Plotlyが最近導入したplotly.expressは、グラフを簡単に描くためのモジュールで、Dashでも使えます。ただし、コロプレス図においてcallback関数を使う場合には、ページがリフレッシュされないという問題がPlotly Community Forumにも報告されています。なので、Dashにてコロプレス図を書く場合にはplotly.graph_objects.Choroplethを利用します。
棒グラフ(Bar Chart)にカラーパレットを適用する
go.Barの属性にmarkerを設定します。
go.Bar(
x=df_selected['Country'],
y=df_selected[item],
marker={
'color': df['人口'], # データ系列をセット
'colorscale': 'viridis' # カラーパレットを設定
}
)
テーブルのフォーマットを変更する
以下の通り、設定します。
dash_table.DataTable(
# 省略
# 特定のカラムのセルを左寄せにする
style_cell_conditional = [
{
'if': {'column_id': c},
'textAlign': 'left'
} for c in ['Country', 'id', 'region']
],
# 1行おきに背景色を変える
style_data_conditional = [
{
'if': {'row_index': 'odd'},
'backgroundColor': 'rgb(248, 248, 248)'
},
],
# タイトル行の背景色を変える・太字にする
style_header={
'backgroundColor': 'rgb(230, 230, 230)',
'fontWeight': 'bold'
}
)
なお、特定行の小数点を2桁にしたいと思って色々と試したけど、うまくいきませんでした。ご存知の方がいたら教えていただけると助かります。
スクリプト全体はこちら↓をご参照ください。