名刺OCR API機能の実装(Google Vision API+独自AIモデル+kintoneとの連携)
本ブログの更新をすっかりご無沙汰しておりました。
昨年春にE資格を取得して、昨年4月には前の会社を早期退職しました。 フリーランスとしてデータ分析やAI案件獲得を目指していましたが、実務経験がないことが足枷となり、なかなか難しいなと感じていたところ、縁あって昨年夏からIT系企業に勤めています。
また、昨年後半には、経産省主催のAI人材育成プログラムであるAI Quest2021に参加したり、ディープラーニング協会の運営のサポートメンバーをしたり、公私にわたり忙しく、なかなかブログ更新ができておりませんでした(言い訳です)。
そうした中で、社内プロジェクトの一環で掲題に関する開発を行いましたので、その概要について説明したいと思います。
1. 全体像

名刺アプリ全体像は、上図の通りであり、「名刺管理アプリ(kintone側)」と「名刺OCR-API機能(GCP側)」の2つから構成されています。 言語としては、kintone側がJavascript、GCP(Google Cloud Platform)側がPythonを利用しています。
そうそう説明が前後してしまいましたが、kintoneとは、サイボウズ社が提供している、webデータベース型の業務アプリ構築クラウドサービスです。いわゆるPaaS(Platform as a Service)に該当するサービスです。さまざまな業種や職種の業務に合わせたオリジナルアプリをノーコードで簡単に作成できますが、標準機能を超えてカスタマイズをしようとするとJavascript(但し、独自性が強いところがあり)を利用する必要があります。
GCP側は以下の機能を使っています。
Vision API
Vision APIは、GCPが提供する機械学習サービスの一種です。 このサービスを利用することで、Googleの持つ画像に関する機械学習モデルを使い、対象となる画像から様々な情報を取得することが可能です。今回は画像からテキストとそのテキストが画像のどの箇所にあるかという位置情報を取得して、利用しています。
Cloud Run
Cloud Run は、いわゆるサーバーレスサービスであり、Docker等のコンテナを実行できる環境です。マシンの構成やトラフィックに応じた自動スケーリングについて心配することなく、サーバーレス HTTP コンテナをデプロイしてスケールするためのフルマネージドなサービスということです。
Cloud Endpoints
Cloud Endpointsは、APIを認証・管理するためのサービスです。
Cloud Storage
Cloud Stroageは、GCPが提供しているオンラインストレージサービスです。Google Driveと比較して、GCPの各サービスとの連携が容易という特徴があります。
Cloud Scheduler
cron のようにジョブの定時実行を行うことのできるサービスです。 任意のHTTPエンドポイントにリクエストを投げることなどが可能です。Cloud Runがサービスを利用していないと停止して、次に呼び出した際にCold Startしてしまうため、立ち上がりまでに時間がかかってしまいます。そこで、本機能を利用して、日中Cloud Runが停止することを避けるために利用しています。
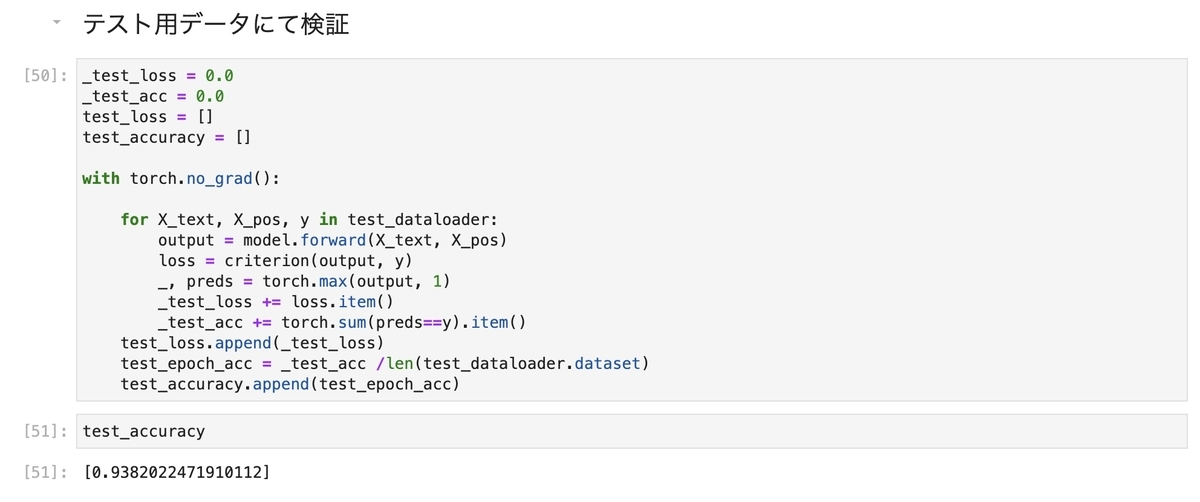
2. 独自AIモデル
GCPではNatural Language APIが提供されていて、その中で「エンティティ分析」という機能があります。具体的には、指定されたテキストに既知のエンティティ(人名、ランドマークなどの固有名詞)が含まれていないかどうかを調べて、それらのエンティティに関する情報を返すサービスです。ただ、名刺の分類で必要な役職やタイトル、部署・住所などが抽出できないし、文章ではなく単語ベースでは精度が悪いので、名刺OCRには適用が難しいので、独自モデルを作成することにしました。
Vision APIでは、画像からテキストを抽出するだけではなく、テキストの位置情報(画像の中でどこにあるかという情報で、テキストを囲む矩形の頂点の位置情報)もデータとして返ってくるので、(双方を利用した方が精度が良いだろうという仮説を元に)双方を利用することにしたものです(体感ではテキストのみを利用したものより精度が良いですが、現時点ではデータが少なく検証までは至っていません😅)。
モデルとしてはテキスト分類でも相応の精度となるCNNモデルを利用しています。CNNだと位置情報を画像化して統合もしやすいのでそうしたメリットもあります。なお、文章等を分類する場合には、辞書を利用して単語毎にTokenizerで分けて数値化するのが通常だと思いますが、名前や会社名・役職等の対象が短いので、文字ベースでテキストを数値化しています。
3. API連携の流れ
- kintoneの名刺管理アプリ等のアプリケーション側で、名刺画像をbase64形式に変換したうえで、以下の通り設定(json形式)してEndpointsにrequestsを送付します
- headersとして
{'Content-Type': 'application/json'} - dataとして
{'requests': [{'images': {'content': base64形式に変換した画像 }]}
- headersとして
- 名刺OCR機能(API)側で処理を行い、その結果を以下の通り返します(json形式)
{'department': 'xxxx部',
'email': 'akatak-blog@xxxx.co.jp',
'fax': '03-xxxx-xxxx',
'location': '東京都xx区xxx-xxx-xxx,
'mobile': '03-xxxx-xxxx',
'organization': '株式会社xxxxxxxx',
'other': 'xxxx, xx"
'person': '',
'tel': '03-xxxx-xxxx',
'title': 'xx長',
'web': 'http//www.xxx.co.jp/'}
- kintoneの名刺管理アプリ等のアプリケーション側で、受け取ったjsonを元に、仕様に基づき適宜データを保存します
4. Google Cloud Platform(GCP)側の処理
- 画像データ(base64形式)をVision APIに送付します。
- テキストデータと位置情報が返ってくるので、それらの情報に基づき、位置が近いテキストをひとまとまりのブロックにします。
- そのブロック毎のテキストに対して、正規表現を利用して、電話番号・ファックス・郵便番号などを抽出します。
- 抽出されなかったブロック毎のテキストを、訓練済みの独自AIモデルに投入し、分類結果を取得します。
- 正規表現に基づいた分類結果とAIモデルによる分類結果を統合し、結果を返します。
5. 実際のAIモデル
モデルの実装はPytorchで行っています。まだ、モデルを訓練するにあたり、Vision APIにより位置情報のある名刺データが少ないため、テキストデータのみに基づくモデル(TextCNNModel)で事前学習をしておき、そこで得られたパラメータを初期値として統合モデル(IntegratedCNNModel)Vision APIにより得られたテキスト+位置情報を元にしたデータに元に転移学習を行いました。
class IntegratedCNNModel(nn.Module): def __init__(self, vocab_size=10000, emb_size=50, filters=128, text_model_initials=None, requires_grad=True): super(IntegratedCNNModel, self).__init__() self.filters = filters self.embedding = nn.Embedding(num_embeddings=vocab_size, embedding_dim=emb_size, padding_idx=0) self.text_conv = nn.Conv2d(in_channels=1, out_channels=filters, kernel_size=(3, emb_size), stride=1) self.text_fc = nn.Linear(128, 64) self.dropout1 = nn.Dropout(0.5) self.dropout2 = nn.Dropout(0.25) self.conv1 = nn.Conv2d(1, 16, 3, 1) self.conv2 = nn.Conv2d(16, 32, 3, 1) self.fc1 = nn.Linear(28800, 1280) self.fc2 = nn.Linear(1280, 6) self.fc_all = nn.Linear(64 + 6, 6) if text_model_initials: self.embedding.weight = nn.Parameter(text_model_initials['embedding.weight'], requires_grad=requires_grad) self.text_conv.weight = nn.Parameter(text_model_initials['conv.weight'], requires_grad=requires_grad) self.text_conv.bias = nn.Parameter(text_model_initials['conv.bias'], requires_grad=requires_grad) self.text_fc.weight = nn.Parameter(text_model_initials['fc1.weight'], requires_grad=requires_grad) self.text_fc.bias = nn.Parameter(text_model_initials['fc1.bias'], requires_grad=requires_grad) def forward(self, in_text, in_pos): x1 = self.embedding(in_text) x1 = self.text_conv(x1) x1 = F.relu(x1) x1 = F.max_pool2d(x1, kernel_size=(x1.size()[2], 1)) x1 = self.dropout1(x1) x1 = x1.view(-1, self.filters) x1 = self.text_fc(x1) x2 = self.conv1(in_pos) x2 = F.relu(x2) x2 = self.conv2(x2) x2 = F.relu(x2) x2 = F.max_pool2d(x2, 2) x2 = self.dropout1(x2) x2 = torch.flatten(x2, 1) x2 = self.fc1(x2) x2 = self.dropout2(x2) x2 = self.fc2(x2) x = torch.cat([x1, x2], dim=1) x = self.fc_all(x) output = F.softmax(x, dim=1) return output
class TextCNNModel(nn.Module): def __init__(self, vocab_size=10000, emb_size=50, filters=128): super(TextCNNModel, self).__init__() self.filters = filters self.embedding = nn.Embedding(num_embeddings=vocab_size, embedding_dim=emb_size, padding_idx=0) self.conv = nn.Conv2d(in_channels=1, out_channels=filters, kernel_size=(3, emb_size), stride=1) self.dropout = nn.Dropout(0.5) self.fc1 = nn.Linear(128, 64) self.fc2 = nn.Linear(64, 6) def forward(self, x): x = self.embedding(x) x = x.unsqueeze(1) x = self.conv(x) x = F.relu(x) x = F.max_pool2d(x, kernel_size=(x.size()[2], 1)) x = self.dropout(x) x = x.view(-1, self.filters) x = self.fc1(x) x = self.dropout(x) x = F.relu(x) x = self.fc2(x) output = F.softmax(x, dim=1) return output
6. 学習結果
転移学習の結果は以下の通りです。
# 学習 tracker = 0 train_loss = [] val_loss = [] train_accuracy = [] val_accuracy = [] model.train() for i in range(epochs): _train_loss = 0.0 _train_acc = 0.0 for X_text, X_pos, y in train_dataloader: tracker += 1 optimizer.zero_grad() output = model.forward(X_text, X_pos) loss = criterion(output, y) _, preds = torch.max(output, 1) loss.backward() optimizer.step() _train_loss += loss.item() _train_acc += torch.sum(preds==y).item() train_loss.append(_train_loss) train_epoch_acc = _train_acc / len(train_dataloader.dataset) train_accuracy.append(train_epoch_acc) _val_loss = 0.0 _val_acc = 0.0 with torch.no_grad(): for X_text, X_pos, y in val_dataloader: output = model.forward(X_text, X_pos) loss = criterion(output, y) _, preds = torch.max(output, 1) _val_loss += loss.item() _val_acc += torch.sum(preds==y).item() val_loss.append(_val_loss) val_epoch_acc = _val_acc /len(val_dataloader.dataset) val_accuracy.append(val_epoch_acc) model.train() print("epoch", i, "\ttrain loss", round(_train_loss, 4), "\ttrain accuracy", round(train_epoch_acc, 4), "\tval loss", round(_val_loss, 4), "\tval accuracy", round(val_epoch_acc, 4))
epoch 0 train loss 25.3956 train accuracy 0.5451 val loss 65.1692 val accuracy 0.5955 epoch 1 train loss 24.1934 train accuracy 0.6259 val loss 64.4132 val accuracy 0.6067 epoch 2 train loss 23.999 train accuracy 0.6353 val loss 64.016 val accuracy 0.6236 epoch 3 train loss 23.0829 train accuracy 0.688 val loss 62.8315 val accuracy 0.6461 epoch 4 train loss 22.7322 train accuracy 0.7011 val loss 62.4082 val accuracy 0.6629 epoch 5 train loss 22.415 train accuracy 0.718 val loss 62.6237 val accuracy 0.6517 epoch 6 train loss 22.3255 train accuracy 0.7256 val loss 61.8551 val accuracy 0.6742 epoch 7 train loss 22.4764 train accuracy 0.7199 val loss 61.0919 val accuracy 0.6854 epoch 8 train loss 22.4273 train accuracy 0.7274 val loss 61.4489 val accuracy 0.6798 epoch 9 train loss 22.3758 train accuracy 0.7312 val loss 61.378 val accuracy 0.6742 epoch 10 train loss 22.227 train accuracy 0.7274 val loss 61.4148 val accuracy 0.6685 epoch 11 train loss 22.2422 train accuracy 0.7312 val loss 61.0007 val accuracy 0.691 epoch 12 train loss 21.6772 train accuracy 0.7688 val loss 57.9652 val accuracy 0.7416 epoch 13 train loss 20.9931 train accuracy 0.8083 val loss 59.2871 val accuracy 0.7079 epoch 14 train loss 21.0462 train accuracy 0.8008 val loss 57.5888 val accuracy 0.764 epoch 15 train loss 20.7282 train accuracy 0.8233 val loss 57.1339 val accuracy 0.7697 epoch 16 train loss 20.1716 train accuracy 0.8553 val loss 53.9223 val accuracy 0.8483 epoch 17 train loss 18.5937 train accuracy 0.9511 val loss 51.2095 val accuracy 0.9045 epoch 18 train loss 18.3057 train accuracy 0.9699 val loss 51.0726 val accuracy 0.9045 epoch 19 train loss 18.3522 train accuracy 0.968 val loss 50.8161 val accuracy 0.9157 epoch 20 train loss 18.2825 train accuracy 0.9756 val loss 51.461 val accuracy 0.8989 epoch 21 train loss 18.1666 train accuracy 0.9812 val loss 50.8358 val accuracy 0.9045 epoch 22 train loss 18.0271 train accuracy 0.985 val loss 50.7952 val accuracy 0.9157 epoch 23 train loss 18.0518 train accuracy 0.9831 val loss 51.1253 val accuracy 0.8989 epoch 24 train loss 18.1432 train accuracy 0.9793 val loss 50.6701 val accuracy 0.9213 epoch 25 train loss 18.0733 train accuracy 0.9812 val loss 51.279 val accuracy 0.8933 epoch 26 train loss 18.0739 train accuracy 0.9831 val loss 50.7902 val accuracy 0.9101 epoch 27 train loss 18.0383 train accuracy 0.9831 val loss 50.4226 val accuracy 0.9157 epoch 28 train loss 17.9971 train accuracy 0.9868 val loss 50.9058 val accuracy 0.9045 epoch 29 train loss 18.014 train accuracy 0.985 val loss 50.8351 val accuracy 0.9101
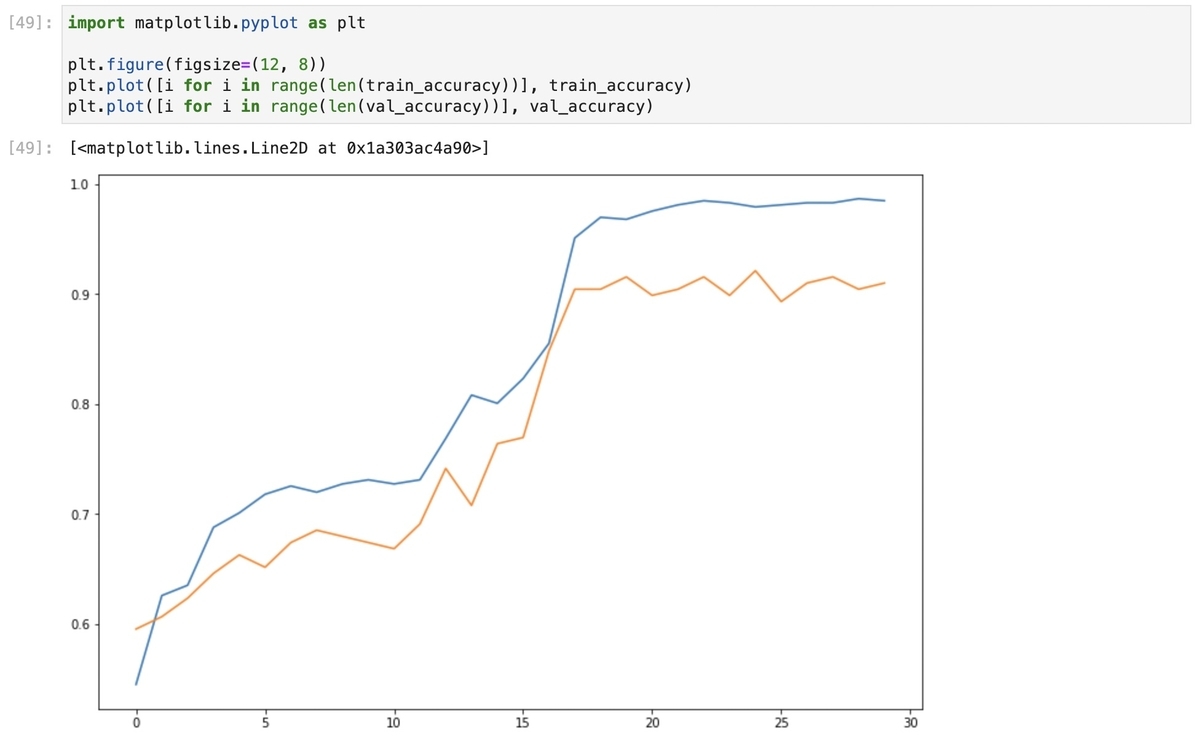
テストデータを適用すると、以下の通り93%の精度となりました。 今後、データを蓄積した上で、精度改善を図っていく予定です。